Div Of Transformation

The fun truly begins in this week.
Once we’ve acquired the basic capabilities to advance from week zero.
We’ll delve into more, more aspects of Terraform and AWS.

We will undertake a comprehensive Terraform module refactoring.
We will also harness the power of tf variables.
- We’re stepping into Terraform Cloud.
- AWS CloudFront will replace S3 for our CDN.
Plus, we’ll wield regex for rule management and ETags to track code changes.
This to name just a few, the rest for you to explore.
- Empower Your Terraform Modules
- Navigating Terraform Config Drift
- Unleash the Power of the Terrahouse Module
- Terraform Refresh and Enveloping
- Mastery of S3 Static Hosting
- Implementing CDN Like a Coding Maestro
- Embracing CloudFront as Code
- Hunting Down CloudFront in the Registry
- Masterful Resource Structuring
- Terraform Content Versioning Strategies
- Commanding CloudFront Cache Invalidation - Unveiling GPT Insights
- Visual Delights with Git Graph
Design Your Terraform Modules
Welcome to 1.0.0 of our week one of the bootcamp where we delve into structuring our Terraform root modules.
We’ve already begun with main.tf. we can accomplish everything within that single file. We can also call that a module.
We will go over making our own module to gain a deeper understanding of Terraform capabilities e.g;
- Organizing your Terraform configurations,
- Working with remote/local state,
- Managing Terraform variables in different ways.
Before starting, consider learning more about the tf structure.
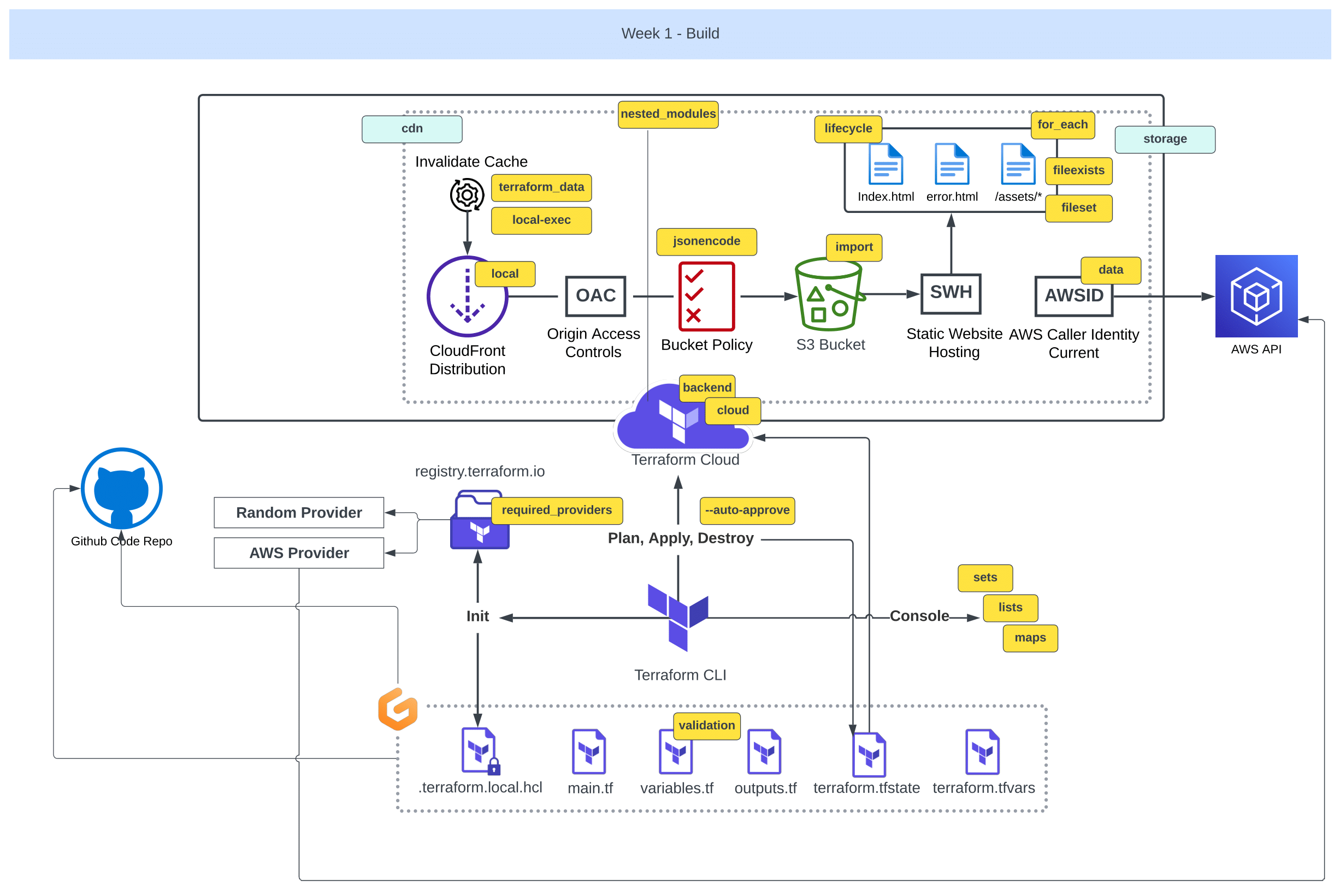
The key is that when we adopt the correct approach to module design, our code will be understood at glance and we’ll also promote its portability.
Others can take that and adapt it to suit their specific requirements.
And this is beautiful!
Terraform Directory Layout
- Create the following strucutre in your project root 👇
🌳 Module Components: ├── 📄main.t: The Core Configuration │ └── 📝 Contains the main configuration for your Terraform resources. ├── 📄variables.t: Input Variables │ └── 📝 Stores definitions for input variables. ├── 📄terraform.tfvar: Variable Data │ └── 📝 Holds data or variable values to load into your Terraform project. ├── 📄outputs.t: Storing Outputs │ └── 📝 Defines the outputs of your Terraform module. ├── 📄 providers.tf: Provider Configuration │ └── 📝 Contains provider configurations and settings. └── 📄 README.md: Module Documentation └── 📝 Provides essential documentation and information about the module.
Module Component Guidelines;
- Recommended structure for organizing your Terraform root modules,
- Suggests moving provider blocks and outputs to dedicated files,
- Highlights the importance of README.md for clear documentation.
| 💭 | Differing opinions may arise regarding the placement of the tf block for providers |
|---|---|
| 💡 | Some advocating for its exclusive presence in the main.tf file. |
| 💡💡 | The choice depends on your team’s preferences and conventions. |
- Please proceed with migrating the
tfblock for providers to theproviders.tffile. - Let’s relocate the output configurations to the
output.tffile. - Bring back the tags we took out previously.
We will use it back to create an additional custom variable.tags = { Name = "My bucket" Environment = "Dev" } - change
NametoUserUuid;tags = { UserUuid = var.user_uuid }
Although we initially considered GPT’s suggestion, we prefer to have it inline.
We added a variable block for the UUID, and within this block, we incorporated the validation process.
| ❌ | Using Terraform Cloud, we coudnt receive a prompt for the variable. |
|---|---|
| ✅ | To address this, let’s transition to remote configuration. |
First, comment out the cloud block and initialize the configuration.
However, it appears we need to revert this migration.
Nevermind, please uncomment the block.
- Let’s manually provide the variable, which should trigger an error when executing and I’ll tell you why
terraform plan -var user_uuid="testingod"We included validation in the variable to ensure it conforms to a specific regex pattern.
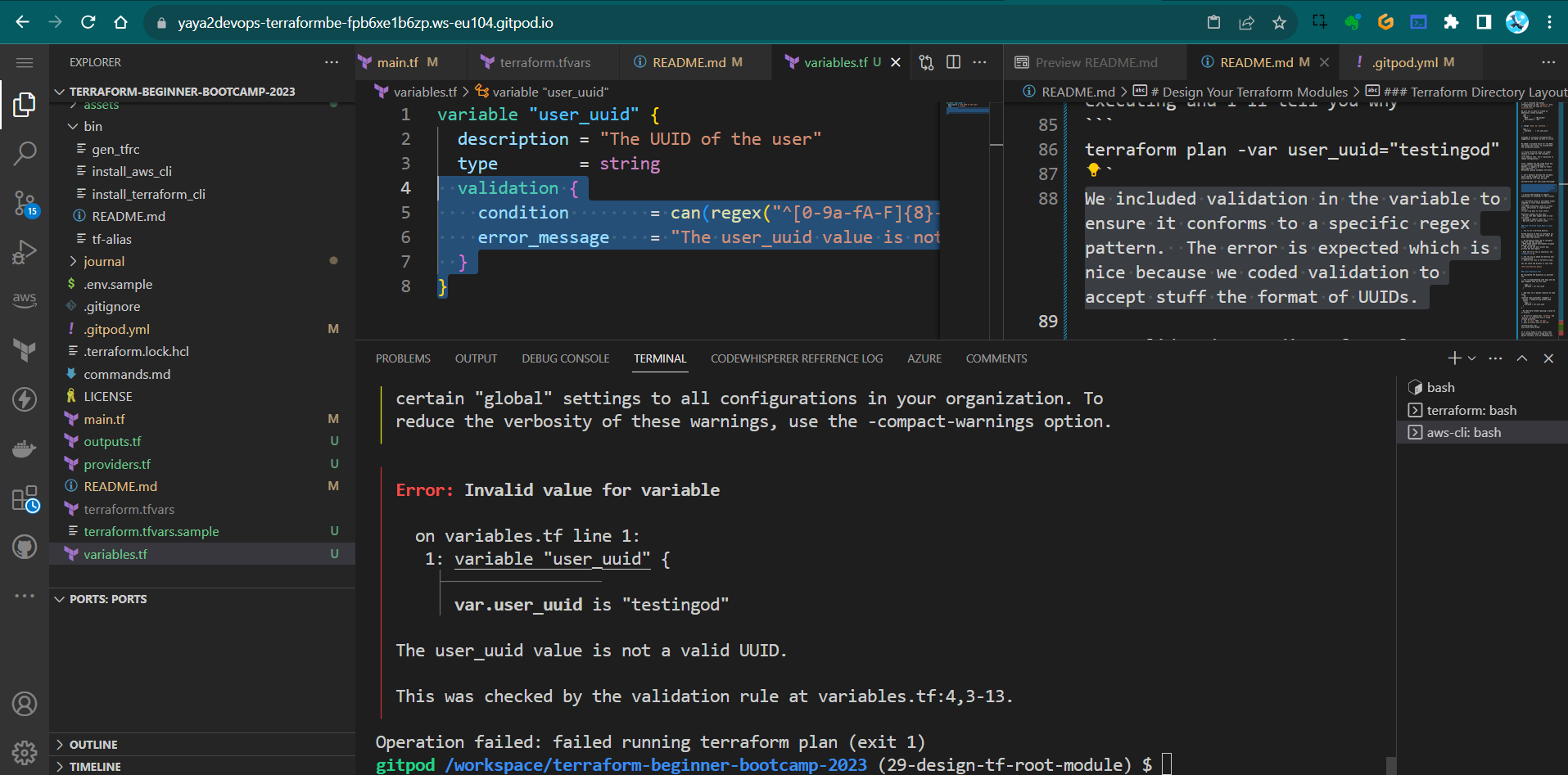
The error is expected which is nice because we coded validation to accept stuff the format of UUIDs.
A solid understanding of regular expressions is essential in this context.
| 🐌 | Terraform Cloud is noticeably slower compared to local state operations! |
|---|---|
| 🏃🏻 | When executing a plan on a local state, the process is significantly faster. |
| 💡 | Let’s go back to local state. |
Potential reasons of this Incl;
- We can test what happen when we lose our state
- Opening to imports (next ver
1.2.0—Here) - Dig into ways to recover state
From Terraform Cloud Back to Local State
- try to run a terrform destroy.
Failed because we have to configure our aws credentials in terraform cloud. We didnt said that before.
- Go Terraform Cloud, go To variables and then add New variable
When asked choose Environment variable and not terraform
- Add one by one your access key, private key and region.
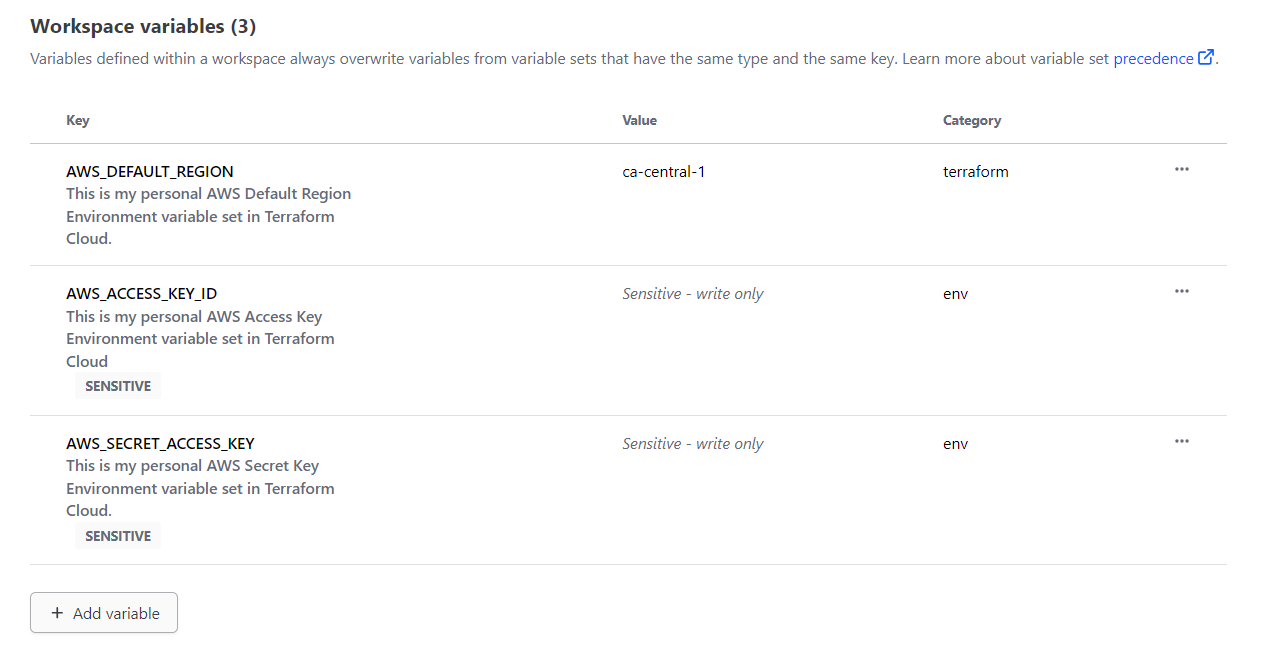
Mark the first two as sensitive, the region is ok.
- You can now go ahead and destroy your infrastructure.
- Observe the runs in Terraform Cloud.
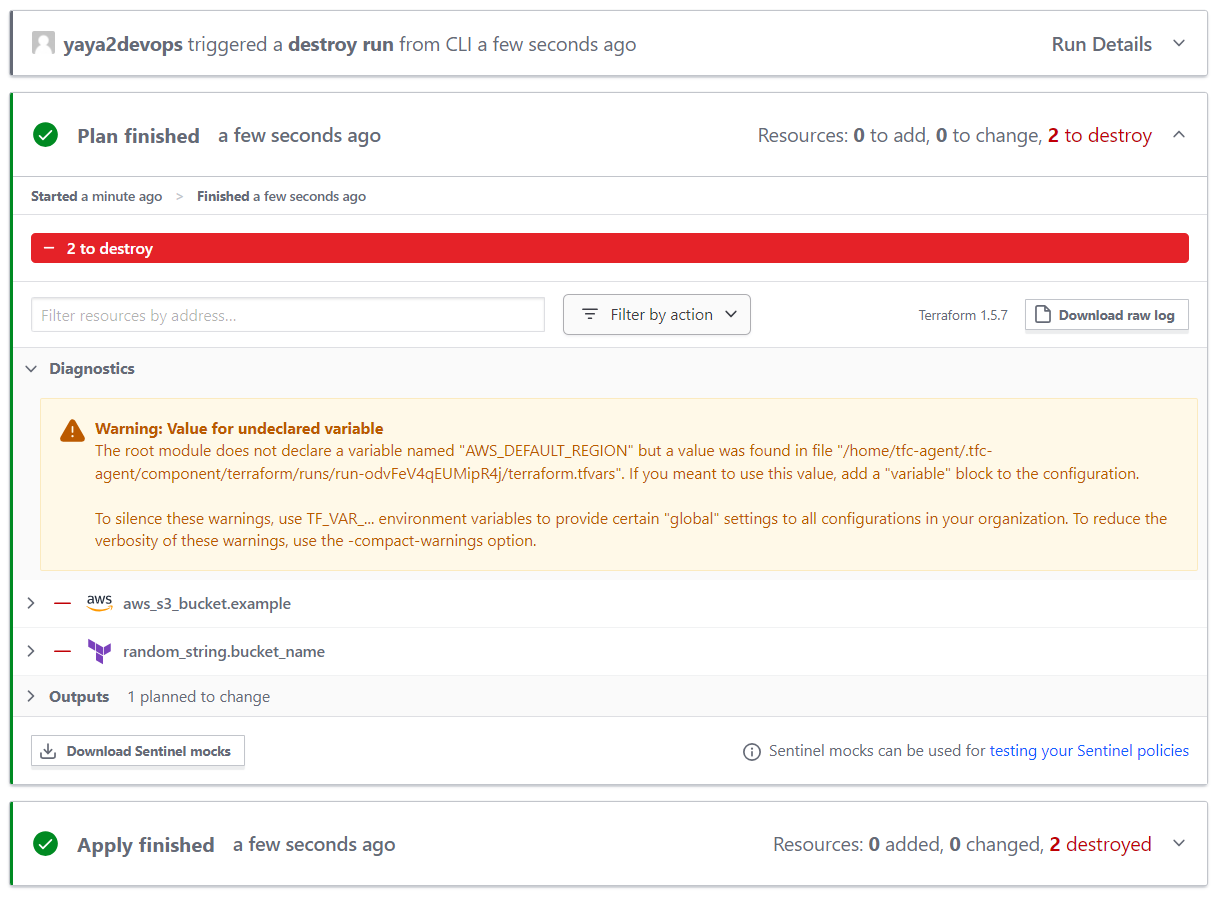
You can check the process in real time.
Local Migration Test
We considered the migration is possible now.
- Try re experimenting with tags and see what happens when you use them.
tags = { UserUuid = var.user_uuid } - Add this to ur bucket resource to look like;
resource "aws_s3_bucket" "example" { bucket = random_string.bucket_name.result tags = { UserUuid = var.user_uuid } }We came here without passing a value to it locally.
- Be sure to remove your
lockfileanddotfileto terminate any tf cloud related processes. - run
tf initthentf plan - give an actual uuid to the var;
terraform plan -var user_uuid="uuid-format"e.g.
terraform plan -var user_uuid="f6d4a521-8a07-4b3f-9d73-2e817a8dcb3d"If it still doesn’t work, ensure that your validation block, along with its parent variable, are not commented out.
variable "user_uuid" { description = "The UUID of the user" type = string validation { condition = can(regex("^[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$", var.user_uuid)) error_message = "The user_uuid value is not a valid UUID." } } - It should work perfectly.
Great and cool! Lets proceed more with our var manipulation skills. - Go to our terraform.tfvars file and include the variable there.
user_uuid=”uuid-format” (looks like toml baby)
user_uuid="f6d4a521-8a07-4b3f-9d73-2e817a8dcb3d"Looks like TOML Baby! whats that? Eeeeh long story.
- Run
tf planonly and it will pick it up.
When doing TF Cloud, You must configure this manually as Terraform variables .
( And not the environment variable we previously used for AWS)
- Create an fork file of the terraform.tfvars with
.sampleextension and add the content.user_uuid="f6d4a521-8a07-4b3f-9d73-2e817a8dcb3d"terraform.tfvars is ignored. Good alternative to not waste this.
- Delete your and try this command to see if it does the job.
cp $PROJECT_ROOT/terraform.tfvars.example $PROJECT_ROOT/terraform.tfvars - It does, now in
gitpod.ymladd the above to the terraform block to look like:- name: terraform before: | source ./bin/install_terraform_cli source ./bin/generate_tfrc_credentials source ./bin/tf_alias cp $PROJECT_ROOT/terraform.tfvars.example $PROJECT_ROOT/terraform.tfvars
This automate the process of getting that example file to a real file on gitpod launch and we are well set!
Terraform Variables 101
I considered adding this part to showcase the different ways you can deal with vars in tf.
We have already showcased some of them.
Variable Input via CLI and Files Flag
- Create a normal variable block wherever required;
variable "region" { type = string default = "us-west-1" } - You can override it using this command;
terraform apply -var="region=new_value" - Or you can create the following json (or HCL) file call it
variables.jsone.g;{ "region": "us-east-2", "instance_type": "m5.large" } - Overide it using that command but with passing the file flag.
tf apply -var-file=variables.json
Terraform will use the values specified in the variables.json file to override the defaults defined in your example.tf configuration.
Terraform Variable Files
(.auto.tfvars and .auto.tfvars.json)
This is cool because it helps terraform knows where to go find vars first.
If you have a configuration named yaya.tf.
Terraform will automatically look for;
- File named
yaya.auto.tfvars - Or file named
yaya.auto.tfvars.json
This will start the variable load values from there.
*.auto.tfvarsis a plain text file where you can set variables like key-value pairs e.g.example_var = "new_value"*.auto.tfvars.jsonis a JSON file where you can define variables and their values. For example:{ "example_var": "new_value" }
Also *.auto.tfvars.json and terraform.tfvars.json are almost the same. Just think about it as a way to design you infrastructure with namings.
Great and cool! My takeaways are;
- You can create as many TF files as needed; they will all be combined.
- To pass an environment variable, use tf var.
- For overrides or new variable settings, employ the var flag.
- In TF Cloud, you can configure both environment variables and TF variables.
- Demonstrates how to define and use custom variables.
- Promotes inline variable usage for improved readability.
- Shows how to include variable validation within var blocks and regex is cool to know.
Also since our plan worked, tf apply changes locally and lose your state to see if we are able to recover it next.
See you in 1.2.0 the config drift.
Terraform Config Drift
1.2.0 started with the idea to answer the following questions.
- How to fix it when you delete your state file?
- Is there anyway you can recover it?
| 🐛 | The feasibility of this depends on the available resources. |
|---|---|
| 📦 | Store your state in a file-like format because not all resources support direct importation. |
Bucket State Is Lost
Our Terraform state no longer manages that bucket.
To get state back, we need to search for the import within Terraform.
Learn more about the import.
To get the import for the s3, follow this process.
- Go to the Terraform Registry.
- Navigate to
Providersand selectAWS. - In the search bar, type
s3to find the AWS S3 related resources. - Look for
aws_s3_bucketand click on it. - On the right-hand side of the page, you’ll find a section labeled ON THIS PAGE.
- Click on
importto go directly to the import documentation.
It should provide you with the necessary import instructions.
import {
to = aws_s3_bucket.bucket
id = "bucket-name"
}
And the direct command;
terraform import aws_s3_bucket.bucket bucket-name
The import just in case.
Take the command to cli and see and change with our bucket named example.
terraform import aws_s3_bucket.example <random-from-ur-aws>
It will import a new state but;
- The import will exclude the randomly generated configuration,
- on tf plan, a prompt to delete the existing bucket and create a new one (
2+ 1-)
Our next task is to retrieve the state in a randomized fashion.
Get Random Back
The method I demonstrated for locating imports in S3 applies to nearly all scenarios.
So, sharpen your direction-finding skills, and I’ll emphasize it once more.
- Go to your desired provider.
- Expand the list of resources.
- Locate the specific resource, such as
random_string. - On the right-hand side, click on
importand take it.terraform import random_string.test testWe’ve named it “bucket_name,” so it functions as follows:
terraform import random_string.bucket_name <paste-random-name-from-s3>The import just in case.
Be aware that importing state may not include the random configuration.
Terraform suggest deleting and recreating the resource along with a random component.
| 💡 | Both are now in their original states. |
|---|---|
| 💡💡 | But in tf plan it seems to think it needs to be replaced. |
| 💡💡💡 | It’s time to terminate random. Was nice |
Bucket The Regex Way
We will proceed by discontinuing the random generation and instead implement a validator.
Similar to the way we did with UUIDs, but this time tailored to meet bucket rules.
- Go to the main.tf
- Delete the Random Provider from
providers.tf.random = { source = "hashicorp/random" version = "3.5.1" } - Remove the Random resource from
main.tf.resource "random_string" "bucket_name" { lower = true upper = false length = 32 special = false } - Remove the bucket configuration
bucket = random_string.bucket_name.resultbucket = random_string.bucket_name.result - Add
bucket = var.bucket_nameinstead.bucket = var.bucket_name - In bucket resource change its name from
exampletowebsite_bucket.resource "aws_s3_bucket" "example" resource "aws_s3_bucket" "website_bucket" - Update the ouptut to not use the random provider and to call our new bucket name.
output "bucket_name" { value = aws_s3_bucket.website_bucket.bucket - add the bucket name to our
terraform.tfvarsand keep a copy interraform.tfvars.samplebucket_name="from-aws" - Define that variable within the variables.tf file.
Ask GPT to generate a Terraform variable definition for the bucket name with validation logic.
Meaning. Ensure it conforms to the requirements for a valid AWS bucket name. - Start with the variable definition with a great description;
variable "bucket_name" { description = "The name of the S3 bucket" type = string - Go ahead with the validation after considering the following rules.
validation { condition = ( length(var.bucket_name) >= 3 && length(var.bucket_name) <= 63 && can(regex("^[a-z0-9][a-z0-9-.]*[a-z0-9]$", var.bucket_name)) ) error_message = "The bucket name must be between 3 and 63 characters, start and end with a lowercase letter or number, and can contain only lowercase letters, numbers, hyphens, and dots." } - Together, fogether to look like this;
variable "bucket_name" { description = "The name of the S3 bucket" type = string validation { condition = ( length(var.bucket_name) >= 3 && length(var.bucket_name) <= 63 && can(regex("^[a-z0-9][a-z0-9-.]*[a-z0-9]$", var.bucket_name)) ) error_message = "The bucket name must be between 3 and 63 characters, start and end with a lowercase letter or number, and can contain only lowercase letters, numbers, hyphens, and dots." } }
Test Drifted Test
Make sure you deleted previous S3s.
- Try giving a bucket name that violates the rule e.g. Yaya2DevOps
- Give a tf plan a try
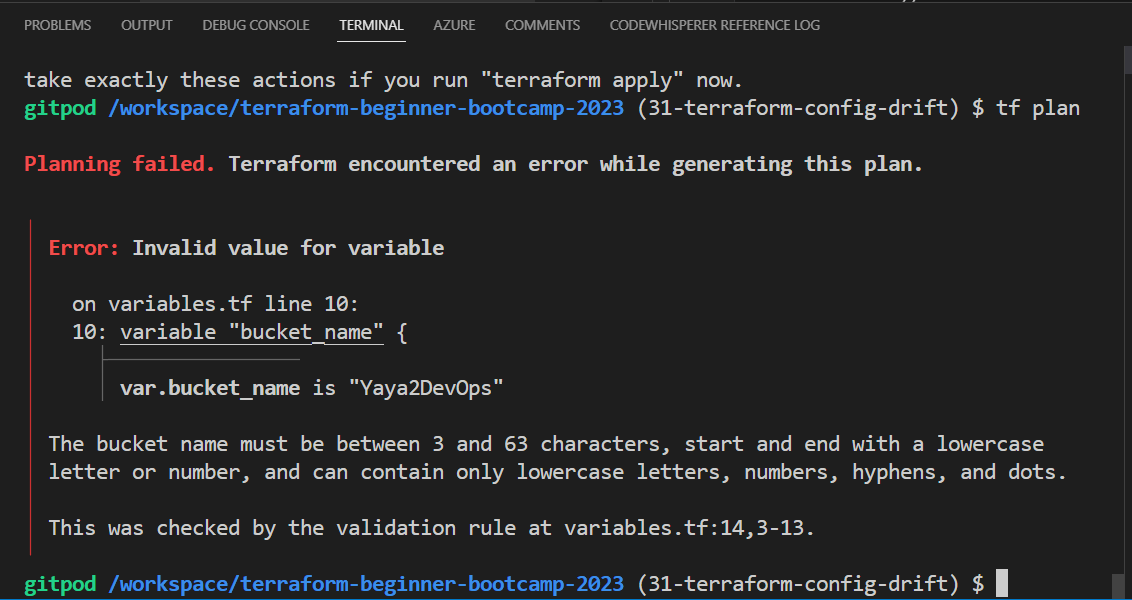
- Double assign it a correct naming.
- Give a tf plan a try
- Run tf apply

You should have your bucket in aws applied.

That was our 1.2.0 configuration drift.
| Consider Regex for vars when validating inputs. |
|---|
| And Yes we did just this! |
The Terrahouse Module
We will walk through the process of creating a Terrafohouse Nested Module and migrate our S3 bucket.
This includes experiencing output/vars calls.
To Recap Just, For You, we’ll be;
- Creating our initial nested module
- Transferring our S3 bucket from the root module to the module.
- Experiencing with output and variable calls working with nested modules.
We started by triple checking The terraform modules Structure again.
When you’re ready, I’m sure you’re excited to go.
Let’s take on this together!
Modules Architecture
Let me explain to you how our infrastructure will be broken down further on the road.
🏡 terrahouse_aws
├── 🗄️ resource-storage.tf
└── 🌐 resource-cdn.tf
- We’ll keep everything related to storage Incl. S3 configurations, in a separate folder file called
resource-storage.tf. - Components related to delivery, Incl. CloudFron,t will reside in another file called
resource-cdn.tf. - Both are withing our 🏡
terrahouse_awsmodule.
Our architectural approach involves isolating components to enhance modularity and maintainability.
Nested Module Init
To begin, let’s establish the directory structure for our Terrafohouse Module:
- Create a new
modulesdirectory, following Terraform best practices. - Inside that, create
/terrahouse_awsdirectory that will host the magic. In this directory, we will have the following essential files and folders. - In
/terrahouse_awscreatemain.tfthat will contain the main configuration for the module. - In
/terrahouse_awscreateoutputs.tfto define our module outputs. - In
/terrahouse_awscreatevariables.tffor mod specific var definition. - In
/terrahouse_awscreateREADME.mdto provide thewhatfor the module. - In
/terrahouse_awsnever miss to createLICENSEto follow best practices in design.
| 📜 | We’ll adopt the Apache License. |
|---|---|
| 👨💻 | Anton Babenko is known for creating many Terraform modules. |
| ✔️ | We can use an Apache License from his work. |
He also likes to travel. I mean yeah. M**e too!**
To continue remmember;
- Each module requires a specified provider.
- If not, Terraform will raise an error.
Refactoring the Root Module
To keep our configuration clean and organized, we’ll make some changes;
- Move the provider configuration from the root directory to
main.tfwithin the module. - Transfer the definition of the bucket resource to
main.tfwithin the module. - Eliminate the root
providers.tfconfiguration because we’ve incorporated it into the module and it got nothing in it we need. - Relocate variables and outputs to their respective places from root to the module.
- Yes make sure to perform a cut operations. I’ll tell you why later.
Modules Are Sources
Now that we’ve moved our configuration to the module level.
The question you are asking is; |❓|How to actually reference them in the root | |—:|:—| |💡|Modules can be imported within another module block|
Here is how;
module "terrahouse_aws" {
source = "./modules/terrahouse_aws"
}
- Input variables can be passed to the module block e.g. UUIDs and BuN
module "terrahouse_aws" { user_uuid = var.user_uuid bucket_name = var.bucket_name }
A powerful point to explore the different sources from which we can reference modules.
These can be local paths-our case, GitHub repos, or the Terraform Registry..
Check it up. The link; I provided you with..
Start Testing Your Module
We linked our module and we can go ahead and give it a try.
To ensure everything is set up correctly
- Use the
terraform initcommand to It will validate our configuration.
It is telling that our AWS bloc is empty new stuff.
Not that deal-Just get rid of it if you want.
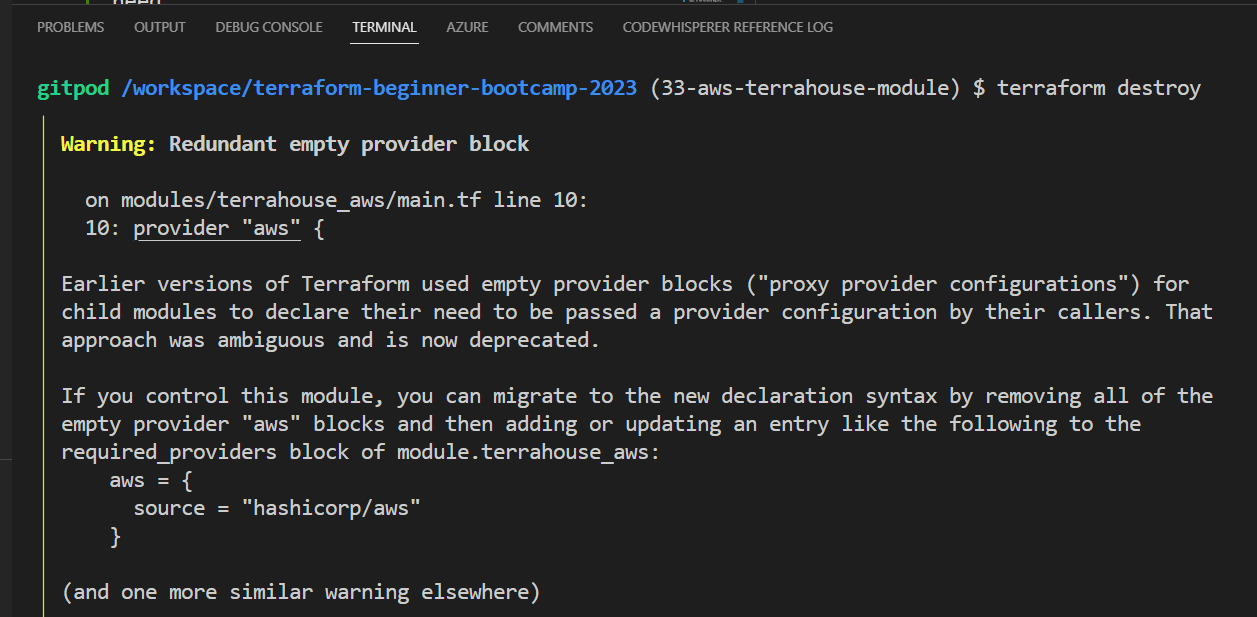
- Run the
tf plan, sometimes I miss out we have alias, to test your module configuration is correct.
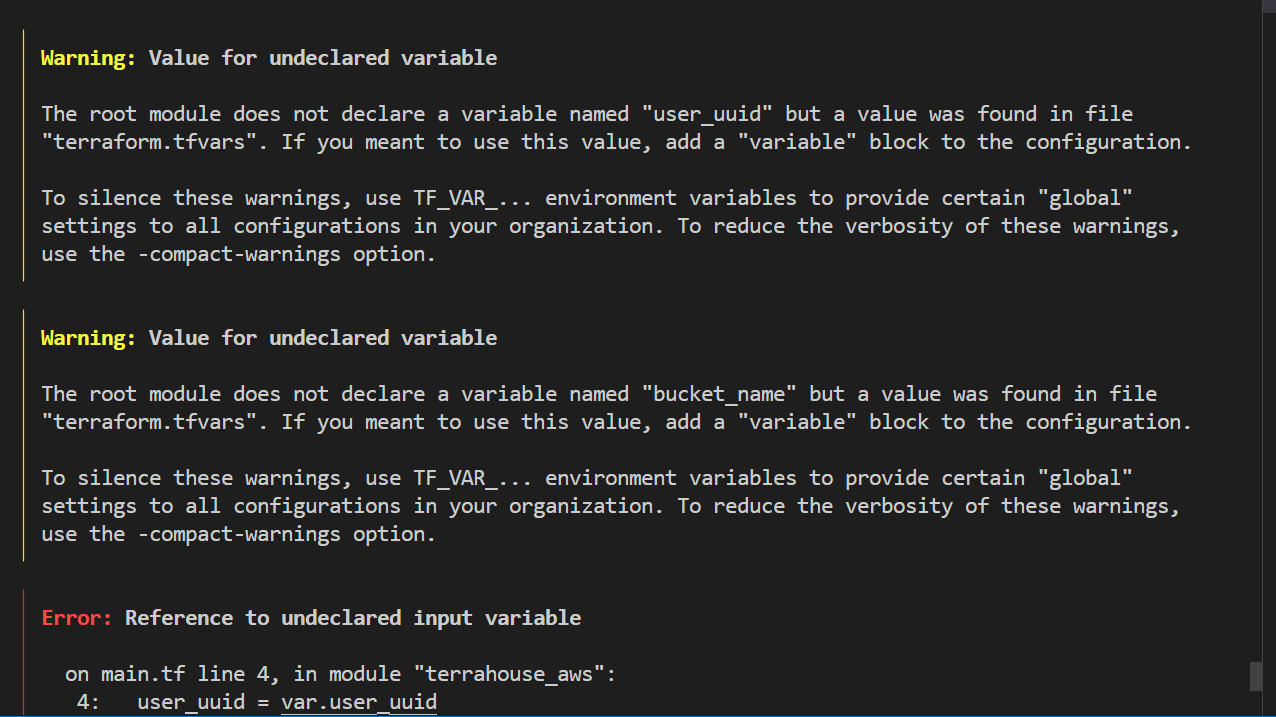
The plan is an error as expetcted. And the truth will follow;
1.1. Handling Variables Validators In Nested Modules
When working with variables and validators, keep in mind:
- Variables need to be defined in both the module and the root.
- Validators, which are already integrated into the module, don’t need to be included in the root.
- Terraform will detect validators automatically.
1.2. Resolve Vars Root Mod
To resolve that, simply define the variables in the root and give it description.
variable "user_uuid"
{
type = string
}
| 💡 | If the naming is accurate.. |
|---|---|
| 💡💡 | It will gather more about the module like magic. |
- Now that you know, do the same for the bucket.
variable "bucket_name" { type = string } - Let’s run
terraform planto observe the plan without errors
Now everything works smoothly.
But I see no outputs.
I am sure I configured my module…
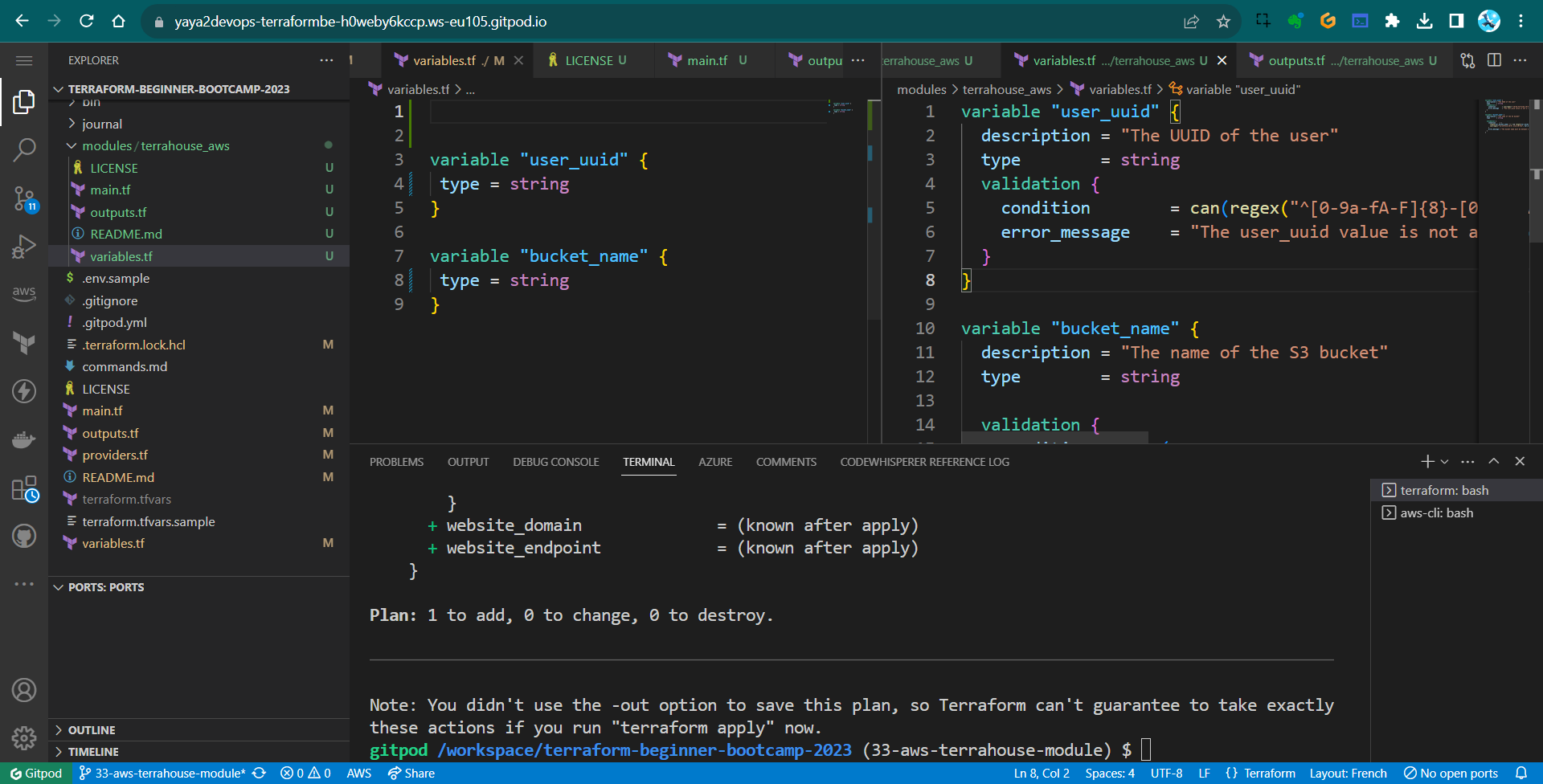
Chill. The turth will follow.
2.1. Outputs In nested Modules
After applying the configuration, you might notice that outputs aren’t visible.
- Run
terraform outputto verify. Nothing to see..Because we have it only in the module as well.
2.2. Resolve Outputs
Outputs defined within a nested module allow us to access them at that level.
To see outputs, they must also be added to the root output. The difference is now we will get it from the module.
- You can access the nested module’s output like this:
module.name-dir.bucket_name. - Give it a great description;
description = "Bucket name for our static website hosting" - Combine code to be as follows;
output "bucket_name" { description = "Bucket name for our static website hosting" value = module.terrahouse_aws.bucket_name }Reflected Thought; nested for a good reason, because its literally nested wihtin this project.
10. Terraform Refresh and Wrap
A good time to employ this command after updating our output code to refresh it baby.
- To dp so, run
terraform refreshafter the output has been updated.tf refresh - Run tf output you’ll be seeing the output;
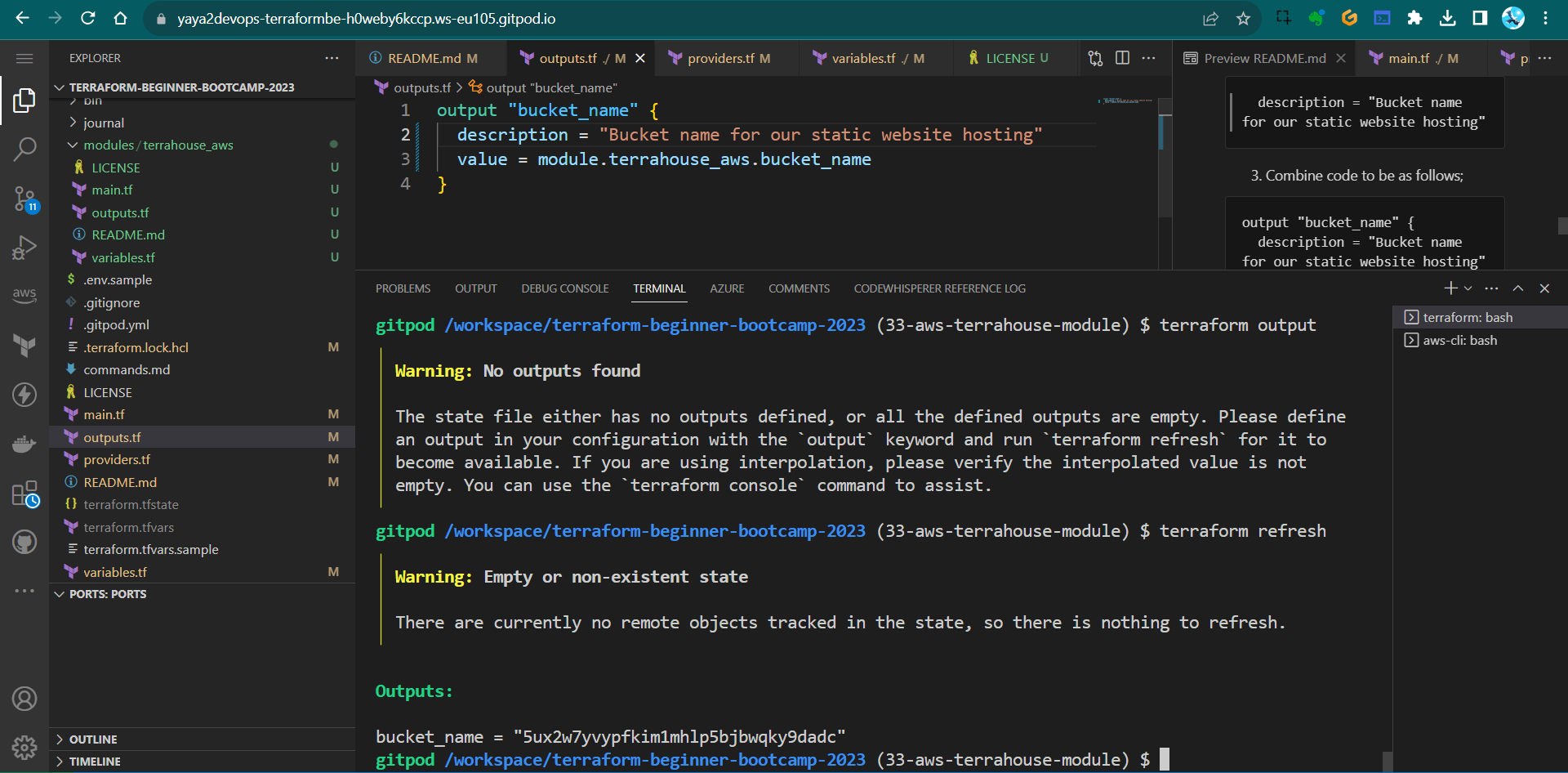
This will synchronize the local state with the actual AWS resources. - run the tf
apply
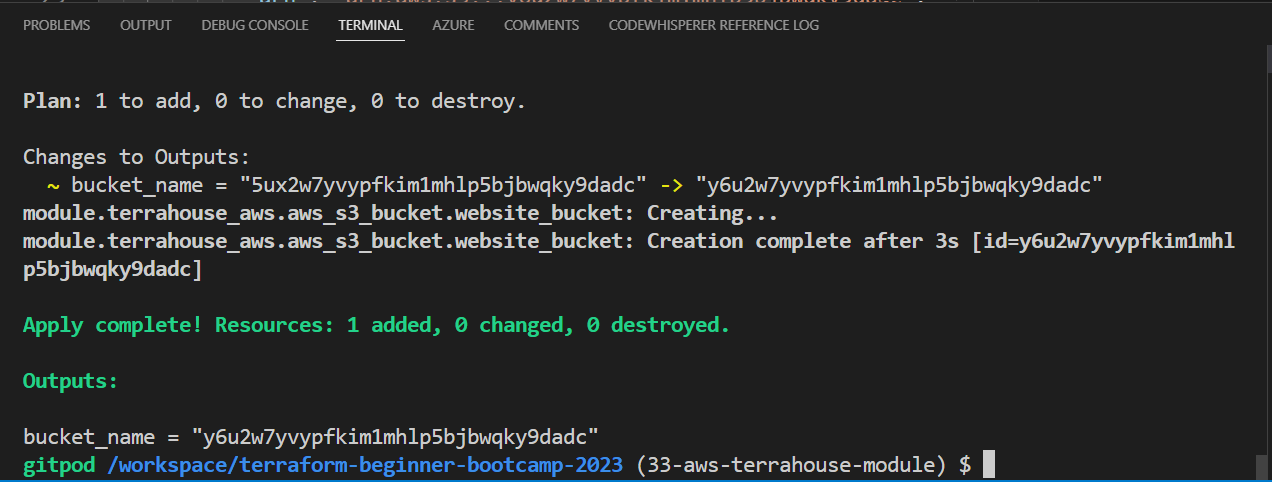
Here you’ll have ur bucket again with the output!
You can also combine refresh with apply;
terraform apply -refresh-only -auto-approve

Great and cool! we’ve successfully did the following;
- created a Terrafohouse Module,
- organized our AWS infrastructure configurations,
- demonstrated effective module referencing and output management.
Future enhancements and additional modules can now be seamlessly integrated into your infrastructure.
Master S3 Static Hosting
Welcome to this 1.4.0 where I’ll elighten you on how to host a static website on S3 using your fingers and Terraform.
Background
We previously performed the setup using the AWS Console.
Host Your First HTTP Server
Let me get you going from your dev env.
- Create
publicdirectory. - Add an
index.html - add some content of your wish.
- Install the
http-serverpackage globally on your system.$ npm install http-server -gThis will allow you to run a simple HTTP server to serve your web app’s files.
- cd to
/public. - Start the HTTP server using the following command:
$ http-server
Now, we aim to take this to s3.
Use S3 For That Instead
STEP 1 Create an S3 Bucket for Static Website Hosting
- Log in to your AWS Console.
- Navigate to the S3 service.
- Click on “Create bucket.”
- Choose a unique name for your bucket (e.g., “ya-ya”) and select a region.
- Leave the default settings for the rest of the options and click “Create bucket.”
Step 2 Upload Your Static Website Files
- In the S3 bucket you just created, navigate to the “Upload” button.
- Select the “index.html” file from your local system and upload it to the S3 bucket.
I did it via the CLI.

I suggest you go do it too.
Step 3 Configure Your S3 Bucket for Static Website Hosting
- In your S3 bucket, click on the “Properties” tab.
- Scroll down to the “Static website hosting” card and click “Edit.”
- Select the option for “Use this bucket to host a website.”
- Specify “index.html” as the Index document.
- Optionally, you can specify an error document (e.g., “error.html”).
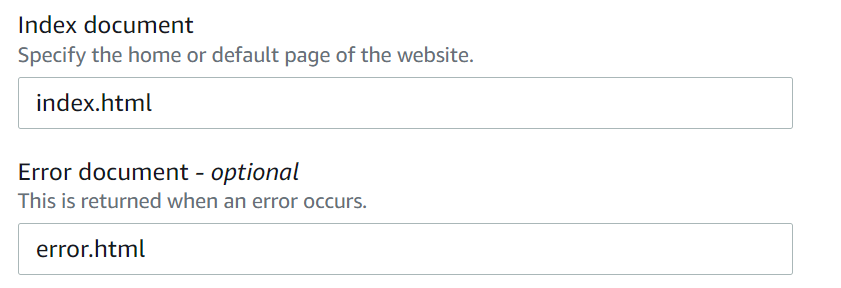
- Click “Save changes.”
- Check your app on the web;
Step 4 Create an AWS CloudFront Distribution
We want to use AWS CloudFront as a Content CDN to distribute our website
- Go to the AWS CloudFront service.
- Click on
Create Distribution. - Choose
Webas the distribution type. - In the
Origin Settings,select your S3 bucket as the origin. - Create the distribution.
Note: To restrict access to your S3 bucket through CloudFront, you can must use an origin access identity and an S3 bucket policy like the one below:
{
"Version": "2012-10-17",
"Id": "PolicyForCloudFrontPrivateContent",
"Statement": [
{
"Sid": "AllowCloudFrontServicePrincipal",
"Effect": "Allow",
"Principal": {
"Service": "cloudfront.amazonaws.com"
},
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::<bucket-name>/*",
"Condition": {
"StringEquals": {
"AWS:SourceArn": "arn:aws:cloudfront::<aws-id>:distribution/your-distribution-id"
}
}
}
]
}
We needed to reconfigure the distribution process due to our failure to define a clear policy.
- Check your new distrubution url and see the site.
Some takeaways from this;
- Distru takes too long to create
- Distru takes too long to delete
We also noticed that we could configure that without taking too long
(Delete not required)..
I mean, guys, we all know that was planned. I just like it.
Code That in Terraform
The configuration provided above will be completely transformed into Terraform code.
- Ask GPT to write u a tf for static website hosting for an s3 bucket.
I mean this looks like something. - In your
main.tfmodule, grap something from that and add it as a resource.
See if it actally works.
No it won’t.
I’ll tell you why. - Run
tf init. Error. - Change the bucket from
bucket = "my-static-website-bucket"toaws_s3_bucket.website_bucket.bucket. - Run
tf initto initialize the Terraform configuration again which should work. - Execute
tf planto review and see if it can do it.
| ⚠️ | Argument is deprecated |
|---|---|
| ❓ | why gpt gave is the wrong thing? |
| ✅ | The aws provider for 5.0 doesnt exist in gpt. |
GPT is not doing it to nowdays.
I personally don’t find terraform changes a lot.
But the provider change year in a year.— Andrew Brown
Back to Home
We can’t rely on GPT
- Go to TF Registry
- AWS Provider
- Click on AWS and see the list.
- Get the
AWS_S3_Bucket_Website_Configuration - Get it from there instead.
resource "aws_s3_bucket_website_configuration" "example" { bucket = aws_s3_bucket.example.id index_document { suffix = "index.html" } error_document { key = "error.html" } routing_rule { condition { key_prefix_equals = "docs/" } redirect { replace_key_prefix_with = "documents/" } } } - Change the example name to
website_configuration - Reference to our bucket from the module;
resource "aws_s3_bucket_website_configuration" "website_configuration" { bucket = aws_s3_bucket.website_bucket.bucket } - Try planning and it should now work;
- tf apply to have the website hosting.
Many people say GPT is god etc, but it’s not the solution for everything, my friend.
This statement is just because this thing is really doing a lot of things already.
Verify From AWS
- Go to S3.
- Verify the bucket.
- Navigate to the properties section.
- Scroll down down down.
- You’ll find the url.
This is good.
But it wont work.
Website Endpoint
So the site is stuck because we have to provide the endpoint to terraform in advance.
- Retrieve the website endpoint URL from AWS S3 properties.
- Add output in Terraform using
website_endpoint, you are pro now.output "website_endpoint" { value = aws_s3_bucket_website_configuration.website_configuration.website_endpoint } - Add a description, it is nice.
description = "The endpoint URL for the AWS S3 bucket website"We also learned that we have to call the output in top level as well.
- Do the same for top level and reference our output.
output "s3_website_endpoint" { description = "S3 Static Website hosting endpoint" value = module.terrahouse_aws.website_endpoint } - in
terraform.tfvarsassign the actual url.s3_website_endpoint="<here>"
Configuration doing good.
But we have to upload the files.
Because still it didnt work.
Files Content Touchpoint
Our goal is to configure terraform so we can upload files as code.
We will create the index and error files and push them with a terraform function.
But.
| ✋ | This is an action you should avoid with Terraform |
|---|---|
| ✔ | Terraform is primarily designed for managing the state of infrastructure |
| ❌ | Not individual files |
Even though Terraform has the capability..
- Terraform discourages such actions.
- If you have files, it’s advisable to handle data management separately.
We will use tf for all three but isnt the best case in production.
We will also discover the existence of provisioners, which allow you to execute commands either remotely or locally.
Using aws_s3_object
- Go to the AWS registry and take
aws_s3_object(notaws_s3_bucket_object). - Specify the bucket, key, and source for your
index.html.resource "aws_s3_object" "index_html" { bucket = aws_s3_bucket.website_bucket.bucket key = "index.html" source = var.index_html_filepath # Ignore this for now #etag = filemd5(var.index_html_filepath) } - Repeat for
error.htmlconfiguration. 🔁resource "aws_s3_object" "error_html" { bucket = aws_s3_bucket.website_bucket.bucket key = "error.html" source = var.error_html_filepath # Ignore this for now #etag = filemd5(var.index_html_filepath)} - Keep it looking as follow;
resource "aws_s3_object" "error_html" { bucket = aws_s3_bucket.website_bucket.bucket key = "error.html" source = var.error_html_filepath
You need to learn the etag progressively.
Create Those Files and Manage with path
Let’s explore whether Terraform console can be utilized interactively for troubleshooting purposes.
- Lets pre test path.root and see;
In the best-case scenario, path.module should always make sense..
- Create a directory and call it
public. - Create
index.htmland add it topublic - Create
error.htmland add it topublic - Remove
etagfrom the section for now (data management magic)#etag = filemd5(var.index_html_filepath) - You have to add these to your root main module block along the source in your module block.
index_html_filepath = var.index_html_filepath error_html_filepath = var.error_html_filepathIt will never work otherwise.
- Plan and apply your content.
- Double check files in S3.
Yes!
Two considerations come up.
- A: You dont want to hardcode your path values.
- B: If I make changes to the file does it work.
A Avoid Your Real Path
⚠️ You should avoid hardcoding values like this to ensure the module’s portability.
| 💡 | One approach we can employ involves… |
|---|---|
| 💡💡💡 | The use of interpolation |
- Instead of the actual path assign the path.root we spoke about for
index.html"${path.root}public/index.html" - Do the same for our
error.htmlfile."${path.root}public/error.html"Make sure you dont do it for
main.tf(our mistake) - Plan it and apply it, it should now give a file!
B Detect File Changes
So this is cool. With what we reached we can take files to the s3 but does it capture the data inside?
- Be aware that Terraform checks file paths but not their content.
- Use an
etagto track content changes. - Add an
etagwithfilemd5for accurate content tracking.
- Change the
index.htmlfile from what it was to something else. - Double change the
error.html - Run
tf planandtf applyand go to the console.
| 👀 | No File Changes! |
|---|---|
| 🤔 | BUT WE CHANGED our files!! |
| 🪄 | The way this works is that it has a source but doesn’t validate the data |
Meaning Terraform state examines the path’s value but not the content of the file within that path.
You can identify file changes by referring to the mentioned etag we removed.
If the content changes, the etag will also change.
- Add the required etag block with the ‘filemd5’ function.
The function creates a hash based on the content.
Good opportunity for you to start exploring about tf functions.
E.g. here is a built in terraform function to check the existance of a file.
condition = fileexists(var.error_html_filepath)
- Now, simply specify the path to the
etagin the same way you did with the source tf planandtf applyand see.
The file will be correctly recognized.
Terraform Vars Instead of path.root
We have the path.root approach, but it’s better to use a Terraform variable.
This allows us to provide flexibility to the module, enabling anyone to change the address. e.g. if you want the index.html file to be stored elsewhere, you can do this effortlessly.
Let’s set up a variable for that purpose.
- Add the variables for index file at the module level within the
variablesblock;variable "index_html_filepath" { description = "The file path for index.html" type = string validation { condition = fileexists(var.index_html_filepath) error_message = "The provided path for index.html does not exist." } } - Add the
index_html_path="/Workspace/etc/public/index"and the error source toTFVARSandTFVARS SAMPLE, along with the new UUID.
(include the entire path; it’s perfectly fine).index_html_filepath="/workspace/terraform-beginner-bootcamp-2023/public/index.html" - Add the vars for the files to the root level
variable "index_html_filepath" { type = string }
Duplicate the resource block to accommodate the error source as well.
- Add the error var in the module level
variable "error_html_filepath" { description = "The file path for error.html" type = string validation { condition = fileexists(var.error_html_filepath) error_message = "The provided path for error.html does not exist." } } - Add the var defined in the root level;
variable "error_html_filepath" { type = string } - Add the error file path in
terraform.tfvarsandterraform.tfvars.sample;error_html_filepath="/workspace/terraform-beginner-bootcamp-2023/public/error.html" - Run tf plan and see.
We’re encountering an error because we need to pass the variables to the rootmain.tffor both index and error. - Do nothing but Run tf plan and see again.
Now it works..after just reapplying.
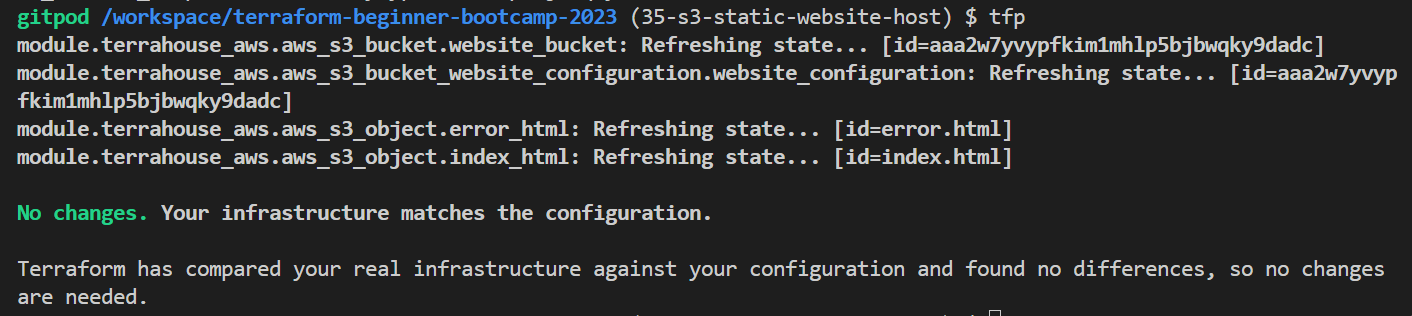
You should remain confident.
It may give false signals due to potential latency issues or other factors very much unknown.
Bonus One Captured
We played more with tags briefly; I’ll write that down for you.
- To tag old stuff run; learn where to get the sha.
git tag <tag_name> <commit_sha> - To delete Local and Remote Tags e.g. 1.1.0
git push --delete origin 1.1.0 - Correct your tag
git tag 1.1.0 <correct_commit_sha> - Push ur corrected tag
git push origin 1.1.0Bonus Two Captured
Also we did this again so I must remember you;
You can hold on your work go somewhere else (diff branch, tag) and get back.
- To temporarily save changes that you’re working on and return to a clean state, you can use Git stash.
git stash save "Your stash message" - When you back just apply your saved changes back
git stash apply
Bonus Three Captured
For more alias and fun stuff to write your CLI;
- Include the following alias along
tfforterraform;alias tfa='terraform apply' alias tfaa='terraform apply --auto-approve' alias tfd='terraform destroy' alias tfda='terraform destroy --auto-approve' alias tfi='terraform init' alias tfim='terraform import' alias tfli='terraform login' alias tflo='terraform logout' alias tfo='terraform output' alias tfp='terraform plan' alias tfpr='terraform plan -refresh-only' - Take my updated script and update yours🫵.
- Test it, do a
tfpinstead ofterraform plan
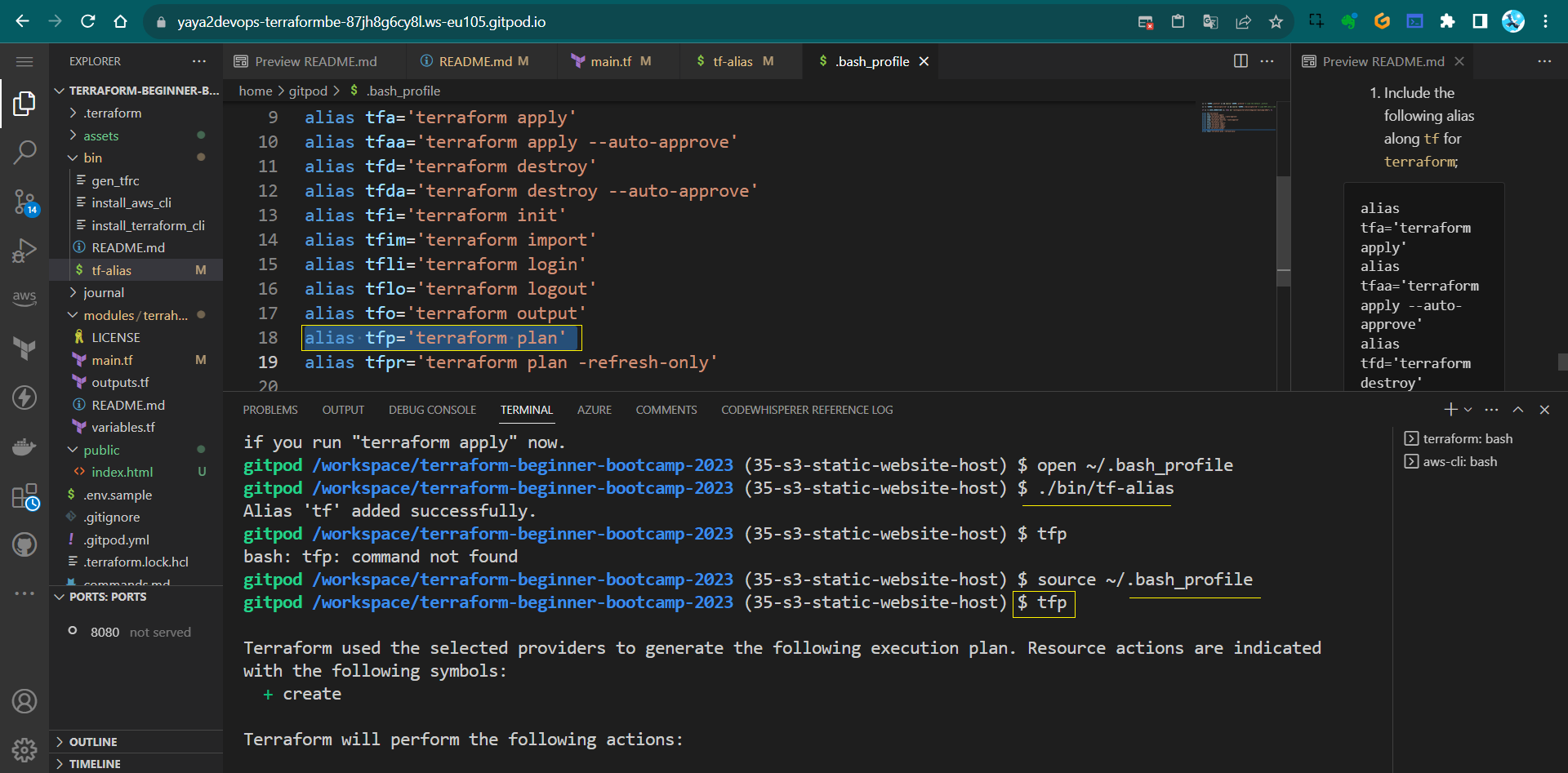
Some campers assets for the 1.4.0 period;
Concluding
A brief conclusion and what to expect next; We can see the content, it changes on apply we still cant access it;
- Discuss the need for a bucket policy.
- Explain the importance of unblocking from the internet. The only way we want to access this is using CloudFront for safer S3 access.
Implementing CDN Via Code
Hello Terraformers, Here we’ll be implementing a CDN to our s3 bucket website hosting using CloudFront to enhance website performance, speed and security via Terraform.
This will be next hooked up to our Terratowns.
CloudFront As Code
- Ask GPT;
Give me aws cloudfront serving static website hosting for an s3 bucket using terraform.So it is giving us something with the bucket (we did that),
And the policy yep good stuff.
Origin Configuration
- For the origin config, it is giving us origin access identity.
- New way of doing it which is origin acces control.
GPT is not aware of this, as it was introduced only last year.
- it can indeed write much terraform.
- But it may not be accurate but junk.
Find CloudFront In Registry
- Go to the Terraform Registry
- Go to providers and click AWS
- top right click documentation
- In search find the AWS CloudFront Distribution
- search the resource:
aws_cloudfront_distribution.
We also see data block, we may proceed to that later. - From the resource take the block from there instead of GPT.
We have an example of an S3 origin configuration for CloudFront.
It looks to be well-structured.
Resource Structuring
We thought to start with the resources to ensure they are grouped together alphabetically for your cute eyes.
- Create
resource-cdn.tf. - Create
resource-storage.tf. - Bring all storage components and paste them into
resources-storage.tfto here.
resource "aws_s3_bucket" "website_bucket" {
# etc
}
resource "aws_s3_bucket_website_configuration" "website_configuration" {
# etc
}
resource "aws_s3_object" "index_html" {
# etc
}
resource "aws_s3_object" "error_html" {
# etc
}
Coding Session Quickstart
- Grab the relevant code from the registry for
res-cdn.tf, but not all of it. - Remove the alias for custom domain.
aliases = ["mysite.example.com", "yoursite.example.com"] - Exclude query string passing is ok
query_string = false - Eliminate cookie passing.
cookies { forward = "none" } } - Retain the “allow all” policy.
viewer_protocol_policy = "allow-all" min_ttl = 0 default_ttl = 3600 max_ttl = 86400 } - Modify caching behavior to keep only the default settings.
default_cache_behavior { allowed_methods = ["DELETE", "GET", "HEAD", "OPTIONS", "PATCH", "POST", "PUT"] cached_methods = ["GET", "HEAD"] target_origin_id = local.s3_origin_id }Meaning, remove both
ordered_cache_behavior. - Specify optional geographical restrictions - Change the type to “none” and remove.
restrictions { geo_restriction { restriction_type = "none" locations = [] } }We could specify for specific countries.
- Tag resources with a UUID, as done previously.
tags = { UserUuid = var.user_uuid } - Specify HTTPS certification for free.
viewer_certificate { cloudfront_default_certificate = true }Note that this won’t work alone because it expects configuration within the
origin{}block.origin { domain_name = aws_s3_bucket.website_bucket.bucket_regional_domain_name origin_access_control_id = aws_cloudfront_origin_access_control.default.id origin_id = local.s3_origin_id }
Lets do it.
Specifying Required Variables resource-cdn.tf
We will now apply a use case for locals. The block serves as a method for passing local variables.
Note that these in the block from registry require definitions.
access control id=origin_access_control
origin id= local.
While we can pass variables as environment variables, this situation presents a good example of when to use locals.
- Define
origin_idas “local” to pass local variables, add local block;local { } - It is locals. just for your awarness.
locals { s3_origin_id = "MyS3Origin" }
Origin Access Control Config resource-cdn.tf
- Utilize the
aws_cloudfront_origin_access_controlblock from the registry.resource "aws_cloudfront_origin_access_control" "example" { name = "example" description = "Example Policy" origin_access_control_origin_type = "s3" signing_behavior = "always" signing_protocol = "sigv4" } - Customize the resource name and use interpolation for the bucket name.
name = "OAC ${var.bucket_name}" - Add a description.
description = "Origin Access Controls for Static Website Hosting ${var.bucket_name}" - Leave network configurations they are correctly set.
signing_behavior = "always" signing_protocol = "sigv4"That should be set, whats left is bucket policy ony..
- change the name of the block to
default.
Adding the Bucket Policy Block resource-storage.tf
I spent a considerable amount of time obtaining that policy.
Should I give it to you?
Let’s help you create it yourself.
- Use the
aws_s3_bucket_policyresource from the registry.resource "aws_s3_bucket_policy" "allow_access_from_another_account" { bucket = aws_s3_bucket.example.id policy = data.aws_iam_policy_document.allow_access_from_another_account.json } - Customize the name to “bucket_policy”.
resource "aws_s3_bucket_policy" "bucket_policy" - Reference the S3 bucket using
website_bucket.bucket.bucket = aws_s3_bucket.website_bucket.bucket
| 👌 | If we have only one of something, we can just name it default. |
|---|---|
| ✅ | We can always revisit—step5 and make them all ‘default’ later |
Instead of this we will code our policy into it.
Code and Define Policy
data.aws_iam_policy_document.allow_access_from_another_account.json
- Define the policy as a JSON-encoded string.
policy =jsonencode() - Go to the cloudfront origin access control and bring the policy to here:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowCloudFrontServicePrincipalReadOnly", "Effect": "Allow", "Principal": { "Service": "cloudfront.amazonaws.com" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::DOC-EXAMPLE-BUCKET/*", "Condition": { "StringEquals": { "AWS:SourceArn": "arn:aws:cloudfront::ACCOUNT_ID:distribution/DISTRIBUTION_ID" } } }, { "Sid": "AllowLegacyOAIReadOnly", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity EH1HDMB1FH2TC" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::DOC-EXAMPLE-BUCKET/*" } ] }In order to include this we have to make some changes..
- Change
:to=for the lines of policy
Thats more of HCL; it serves as the foundational syntax underpinning Terraform, shaping Terraform into what it is. - We only require one statement; specifically, take the second block starting with ‘sid’.”
{
"Sid" = "AllowLegacyOAIReadOnly",
"Effect" = "Allow",
"Principal" = {
"AWS" = "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity EH1HDMB1FH2TC"
},
"Action" = "s3:GetObject",
"Resource" = "arn:aws:s3:::DOC-EXAMPLE-BUCKET/*"
}
In the initial statement, we are indeed interested in ‘sid,’ ‘effect,’ ‘version,’ ‘principal,’ and ‘action’..
However, our target for modification is the bucket.
"Resource": "arn:aws:s3:::DOC-EXAMPLE-BUCKET/*"
- Incorporate interpolations using
${aws_s3_bucket.website_bucket.id}.
We have conditions that require us to narrow it down to either ‘distru’ or ‘acc’.
It’s requesting an account ID.
This is an effective way to use data.
Data Block
- When navigating to the AWS provider and exploring the registry, you will find a comprehensive list of data sources available.
- In our case, we aim to utilize something for
aws_idwithin the policy. - For this purpose, we can employ
aws_caller_identity.
We’ve previously used it to validate our account in the CLI.
Check it out.
data "aws_caller_identity" "current" {}
output "account_id" {
value = data.aws_caller_identity.current.account_id
}
output "caller_arn" {
value = data.aws_caller_identity.current.arn
}
output "caller_user" {
value = data.aws_caller_identity.current.user_id
}
Get account ID
Consequently, we can easily retrieve the account ID.
- Add the following to the main.tf in ur module.
data "aws_caller_identity" "current" {}Now, you can reference this data wherever you need it; that’s all it takes.
- We can access the value, which is
data.aws_caller_identity.account_id. - In our data policy, incorporate
data.aws_caller_identity.account_idinto the interpolation."arn:aws:cloudfront::${data.aws_caller_identity.current.account_id} - Add the interpolation using ${}.
- avigate to the CloudFront distribution registry link, find the reference, and identify the ID.
- Include the variable for the ‘distrubution’ in the interpolation as well.
:distribution/${aws_cloudfront_distribution.s3_distribution.id}"We could have opted for using an ARN..This will do the exact job with less code..
"AWS:SourceArn": data.aws_caller_identity.current.arnBut. Our preference was to utilize the data source! And learn.
- Test
tf initandtfp
- Test
Error 1: We mistakenly used local instead of locals.
Error 2: The ‘id’ in the bucket policy resource was placed outside the curly braces, it should be inside like this: {.id}.
Both are corrected now in the instruction…
I am just saying. If not so, remake step 10.
- go to Cloudfront and click the URL.
It worked we have an URL, but the site is not launching..
It is downloading us the index.html file.
Why URL equals Download
The mystery lies in the fact that while we referenced the file, we didn’t specify its file type to Terraform.
- Navigate to the registry:
aws => s3_object - find the “content_type” argument reference on the right table of contents (TOC).
- In the resource block for
"aws_s3_object" "index.html", includecontent_type="text/html".resource "aws_s3_object" "index_html" { content_type = "text/html" } - Similarly, for
"aws_s3_object" "error.html", addcontent_type="text/html"as well.resource "aws_s3_object" "error_html" { content_type = "text/html" } - tfp and tfa and check the link again.
| ❓ | Still downloading the file..Why |
|---|---|
| 💡 | It’s a CDN, and It caches values |
| 💡💡 | To ensure it functions properly |
| 💡💡💡 | You need to clear the cache |
Clear CloudFront Cache
We will clear the CDN cache in AWS CloudFront by creating an invalidation.
- Go to CloudFront.
- Click on your distribution.
- In the Invalidations pane, select “Create Invalidation.”
- Add the following:
/*
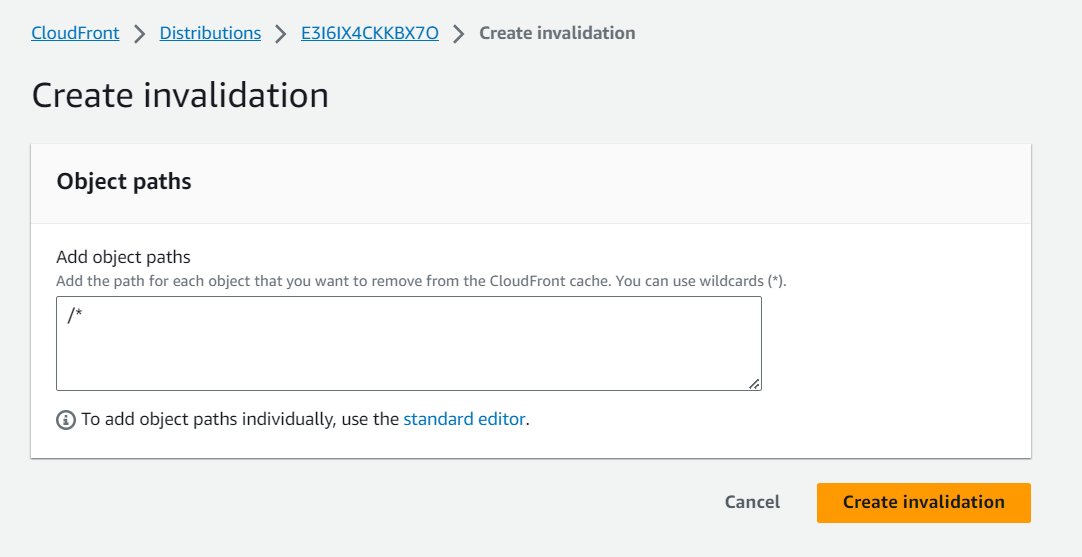
This will clear the cache of all items.
Alternatively, you can specify individual items one by one.
After it’s done, double-check the URL. Still dowloading….
Troubleshooting
I have reservations about the bucket’s reliability.
- Let’s remove it, as it might lead to configuration drift – that’s perfectly acceptable.
- Create a new index file and request an HTML file with a well-structured header and an appealing design from GPT.
- Ensure that the HTML is improved and any errors are corrected.
- Simply map out a plan and execute it to upload the files once more.
- Now, we need to head over to CloudFront and perform another round of validation…
| 🆗 | It’s time to streamline these processes and automate them |
|---|---|
| ✨ | Any modifications should trigger automatic updates. |
| ✨✨ | This is something we should explore soon |
✅Quick update: We tried it from bucket—It is working;
✅Check the CloudFront URL—It’s working perfectly now!
We’ve explored various effective strategies to overcome numerous challenges.
If you’ve been following along, I must commend your excellent efforts!
1.5.0 Considerations
CloudFront can be quite a headache and It truly demands significant time to spin up.
- Consider using the
retain_on_deleteflag. - We can reference a created policy in IAM instead.
We’ve addressed data sources, locals and now the next step is to explore further cache invalidation streamline.
Terraform Content Versioning
Hey Terraformer, I’ll outline the process of implementing content versioning for our S3 bucket serving a website via CloudFront in this 1.6.0.
Note: This step should be done prior to cloudfront distribution caching.
Bootcamper Context
Content versioning is essential for efficiently managing your files content and ensuring that changes to your site files only when necessary.
- We want to validate the cache when the file changes.
- We want to be more explicit about which version of the website we are serving.
- We don’t want cache is cleared entirely when any file changes
The last is very expensive call rather only what specified.
Instead, implement content versioning to cache only when desired.
- This is version one of the site;
- This is version two of the site;
We want it to be that explicit.
Versioning Your Website
We will clearly define different versions of the website (e.g., V1, V2..etc).
Starting with defining Content Version in Terraform Variables
- Open the
terraform.tfvarsfile and addcontent_version=1(or the desired version).content_version=1 - Add
content_versionto your main Terraform module call undersource.content_version = var.content_version - Implement a Terraform variable for
content_versionthat only accepts positive integers starting from one in your modulesvariables.tf.variable "content_version" { description = "The content version. Should be a positive integer starting at 1." type = number validation { condition = var.content_version > 0 && floor(var.content_version) == var.content_version error_message = "The content_version must be a positive integer starting at 1." } } - Include that in the variable call in
variables.tfin the module level.variable "content_version" { type = number }
Configure Resource Lifecycle
We want to trigger thhose in particular cases using Lifecycle
It enables you to respond to various actions on a resource, such as its creation, deletion, and other relevant events.
- Navigate to the
resource-storage.tffile. - Look for the S3 resource lifecycle.
resource "azurerm_resource_group" "example" { # ... lifecycle { create_before_destroy = true } } - Add a lifecycle configuration to the
index.htmlanderror.htmlresources in s3 bucket object.lifecycle { ignore_changes = [etag] } - Exclude the
etagfield within the lifecycle.ignore_changes = [etag]
Learn more about lifecycle in terraform from here.
Test 101
Observe the behavior when changes are made:
- Comment both the lifecycle configurations.
#lifecycle { # ignore_changes = [etag] #} - Make changes to the files and observe Terraform plan and apply results.
- Uncomment the lifecycle configurations and change file
- run
tfp - observe the behavior again.
This is ignoring the etag.
To make it so, we have to code the trigger.
Triggering the Changes
Our approach involves closely associating it with the respective resource. To trigger changes based on the content version, we’ll use Terraform’s terraform_data resource.
Traditionally, you would associate a null resource and a provider.. in the way offered by HashiCorp.
- Configure the
terraform_dataresource to manage content versions as if they were regular resources.resource "terraform_data" "content_version" { input = var.content_version } - Connect the content version to the resource lifecycle to trigger updates when the content version changes.
replace_triggered_by = [terraform_data.content_version.output] - make sure its place for ur index.html lifecycle like this:
lifecycle { replace_triggered_by = [terraform_data.content_version.output] ignore_changes = [etag] }
When we modify our version, it will be treated and managed in a manner similar to a resource.
Test 202
- Run
terraform planand see if it actually decide to change it;
It does work because tf data never existed.
But. It doesn’t appear to be triggering the content as expected… - run
tfaaand dotfpto see no change. - Change some of the content and do
tfp.
It also didn’t incorporate the changes…
Test 303
Because we hadn’t altered the version.
- let’s update it to ‘2’ in the tfvars file.
- run tfp and observe now.

It’s still not producing any changes.
- Do a
tpamaybe tfp is lying to us.
Still…Terraformers…
Test 404
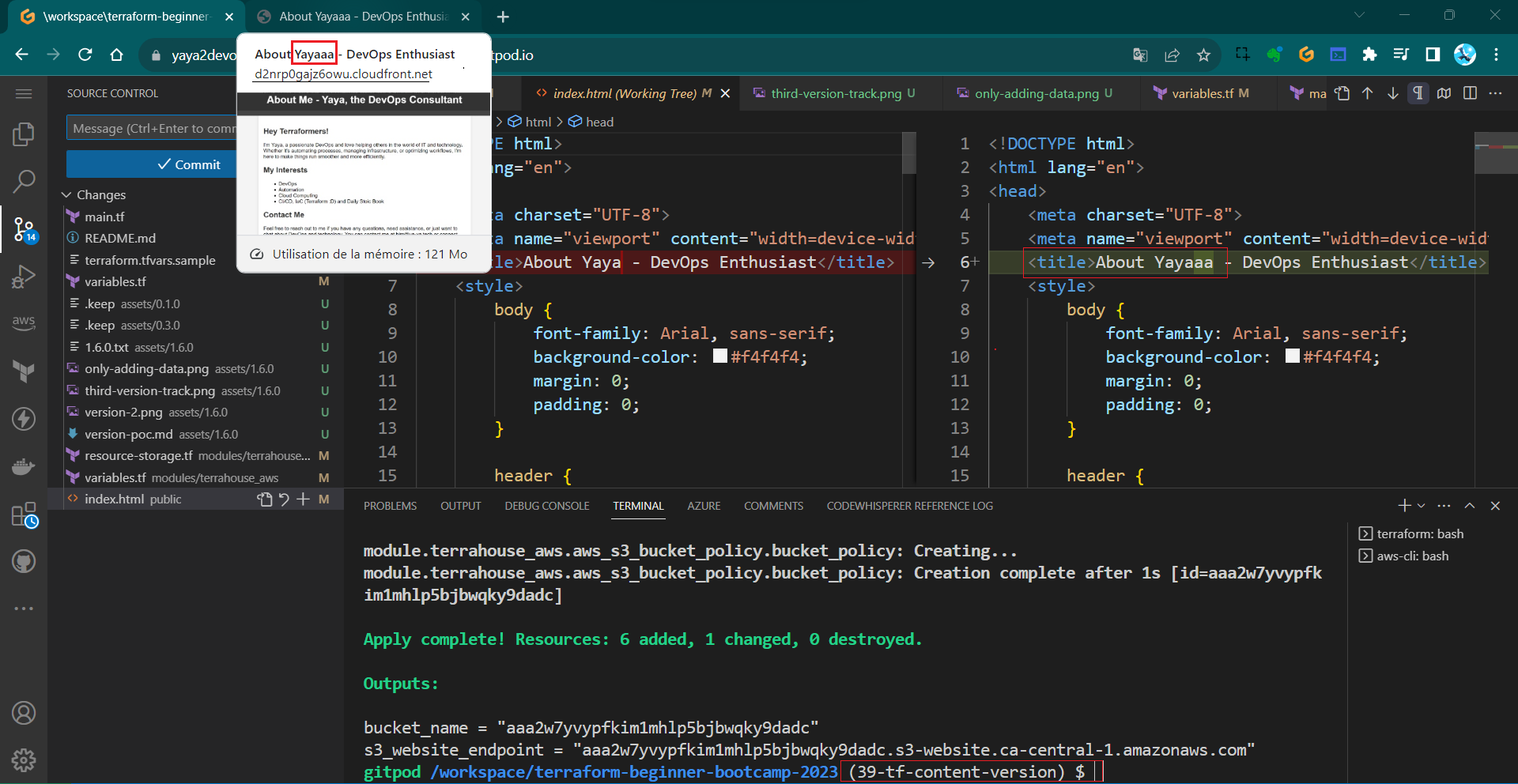
The issue arises because we changed the variable in the tfvars file but didn’t reference it in the module block in the our main.tf at the root level.
- Change content_version = 2 to e.g. var.content_version=3.
- Run
tfpagain. - Observe that the change will now take effect.

Notice that the updated version is correctly influencing the process.
Conclusion
We can now manage and trigger changes to our website more efficiently.
Each content version will be handled like a resource,
- This implementation won’t trigger cache clearing in CloudFront.
- This aspect will be addressed in version
1.7.0of our project.
FYI again, Terraform is not be the optimal tool for this specific task but for the learning.
Invalidate CloudFront Distribution
Welcome to the process of invalidating cache using Terraform, with a focus on local execution.
But wait, with the latest Terraform version, cache invalidation seems elusive, right?
Fear not, for we’re about to unveil the solution.
We will learn about Terraform data blocks and null resources to achieve this task.
GPT is again Mhh
Lets get something out of GPT.
Hey invalidate cloudfront distrubution using Terraform
This is using the null resource which is pretty good.
This is actually the way we do it.
| 💫 | Null resource served its purpose in the past |
|---|---|
| 💡 | But now, |
| 🆕 | The torch has been passed to data |
Background and Context
Invalidate cache is a critical operation in managing our CDN.
We aim to automate cache invalidation whenever our content changes, using a background CLI command if that make sense.
| 🙃 | Provisioners such as remote exec and local exec are discouraged |
|---|---|
| ✅ | Other tools like Ansible are better suited for these tasks. |
Some companies are still engaged in this practice…
Terraform is primarily used for managing the state of code rather than configuration management.
We will be doing it anyway because we get to do more advanced concepts in terraform.
Terraform Data
Terraform data blocks are the preferred method for managing data resources in Terraform configurations. They don’t require the installation of additional providers and are recommended over null resources for this purpose.
Local Execution with Null Resources
Local execution using null resources can be useful when you need to run commands on your local machine. In this case, we will use local execution to trigger cache invalidation.
Implement Invalidation
We also want to activate a provisioner.
The local exec command runs on the local machine where ur running tf.
If we use Terraform Cloud, the local machine should align with the computing resources provided by Terraform Cloud.
You can also use remote exec, which enables you to connect to a remote computer and perform SSH etc..
We will make it simple here with local compute..
- go to
resource-cd.tfand add the reosurce terraform_data and name itinvalidate_cache.resource "terraform_data" "invalidate_cache" {} - Trigger the content versions replace:
triggers_replace = terraform_data.content_version.output - Create provisioner block for our local exec inside the
terraform_data.provisioner "local-exec" { } - Use a heredoc block like this to pass the command:
provisioner "local-exec" { command = <<EOF # Your commands here # E.g. our invalidate cache EOF }You can also add whatever, the point is to end it with the same, let me clarify.
provisioner "local-exec" { command = <<command # Your commands command } - Add inside it the required invalidation api command from aws sdk:
command = <<COMMAND aws cloudfront create-invalidation \ --distribution-id ${aws_cloudfront_distribution.s3_distribution.id} \ --paths '/*' COMMAND - Verify your provisioner block for
local_exec;provisioner "local-exec" { command = <<COMMAND aws cloudfront create-invalidation \ --distribution-id ${aws_cloudfront_distribution.s3_distribution.id} \ --paths '/*' COMMAND }Be aware that Provisioners are a pragmatic approach. They have the capability..
- After coding
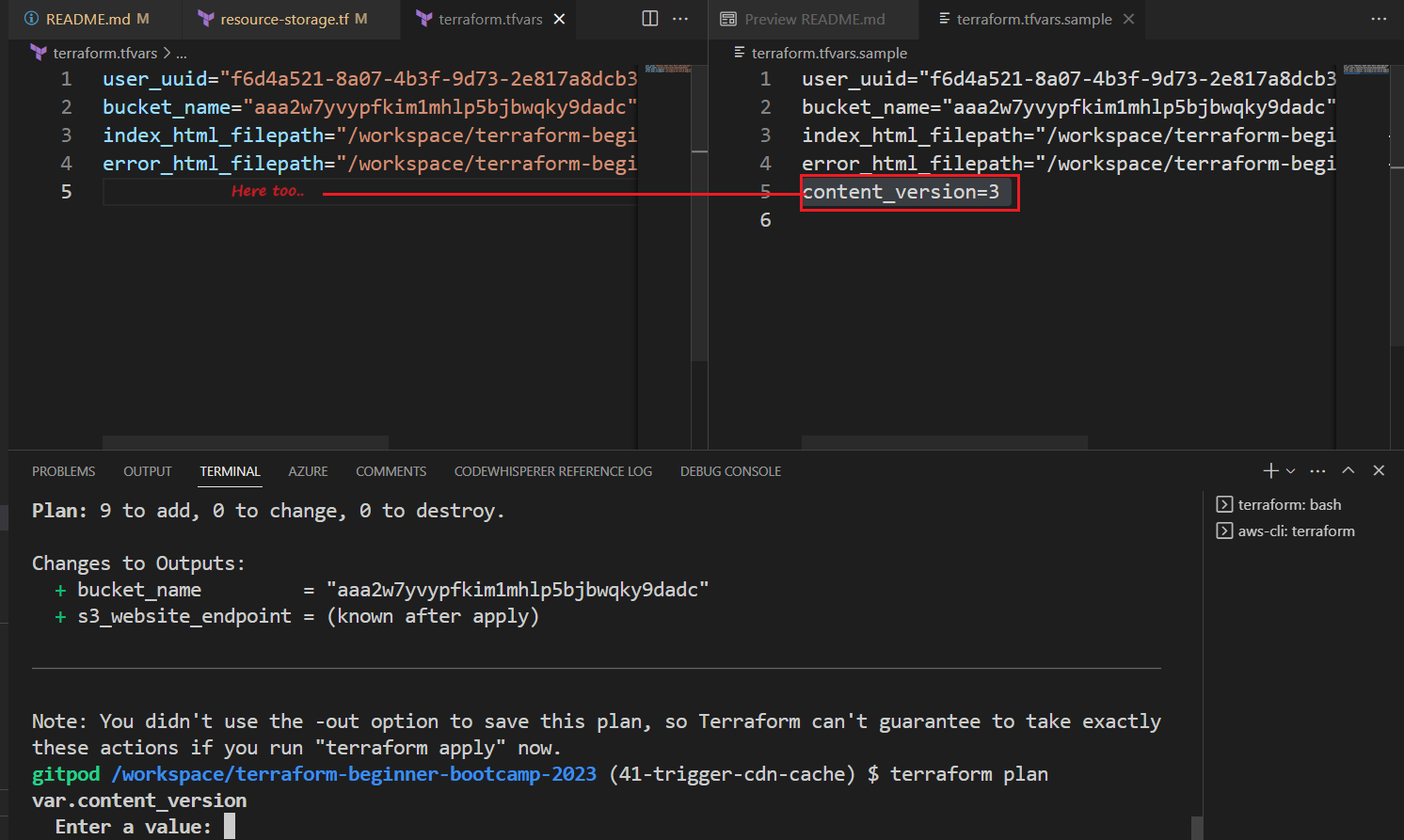
resrouce-cdn.tf, run tfp
Now it’s asking for the current version..?
Because the content_version=x wasn’t configured.
To trigger cache invalidation, you must increment the content version.
- reset the value in your
terraform.tfvarstocontent_version=2 - run tfpaa this time.
Good and cool.
Output Configuration
One thing I’m looking for here is the CloudFront distribution output.
To monitor the status of your cache invalidation.
- add the CloudFront distribution output to your Terraform module.
output "cloudfront_url" { value = aws_cloudfront_distribution.s3_distribution.domain_name } - And add the definition in your root
variables.tfroot outputs.output "cloudfront_url" { description = "The CloudFront Distribution Domain Name" value = module.terrahouse_aws.cloudfront_url }
Performing Cache Invalidation
Lets try to change something and see.
Perform the following steps to invalidate the cache:
- Run
terraform planto verify your changes. - Run
terraform applyto apply the changes and trigger the cache invalidation. - Check the output to verify the new version and CloudFront distribution information.
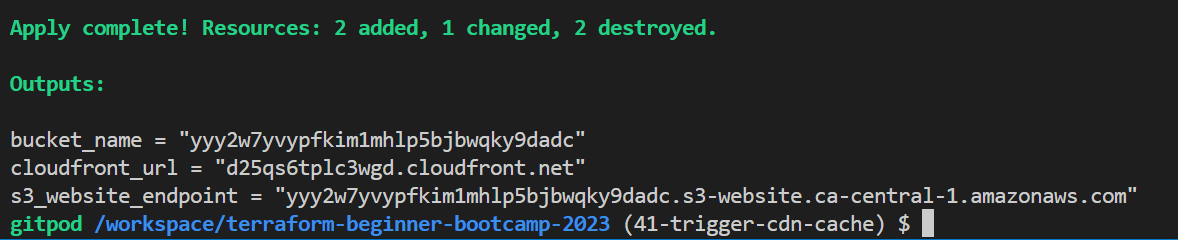
- Start visiting your cloudfront distribution.
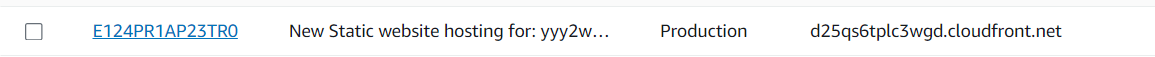
- Visit your CloudFront invalidation and observe that you have one set as directed in the command.
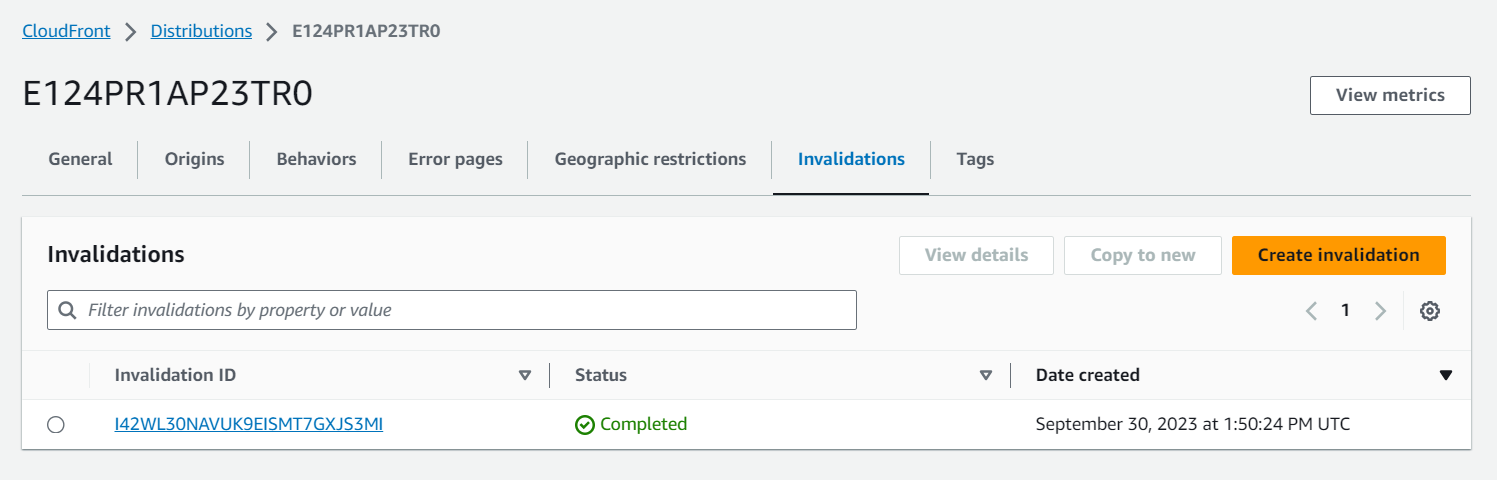
The cache is applied as required.
Reverting Changes And More..
To back clean for our next version, revert the changes by running terraform destroy and setting the content version back to the previous value 1.
If you followed, your process is now automating the cache invalidation process using Terraform.. Making your content delivery more efficient and reliable!
Consult some good stuff we’ve done here.
Also a funny error I had.
And that’s what 1.7.0 is for. The bootcamp is indeed a beginner level.
Terrahouse Asset Management
Hey Terraformer, wrapping up our first week (technically second because we started from zero), we’ll work on asset management process for our website to include images, JavaScript, and stylesheets and moree to make Terrahouse look impressive in TerraTown!
We also aim to create a page that connects W1 and W2, possibly as a hub!
Improvisation
Let me freestyle for you my experience and what I think about this.
An asset is something that has the potential to add value to you, that is why it is called that.
Computer files especially those with more visual are considered assets because once throwed to the system, they’ll get consumed and you can get a benefit out of it.
Videos are the highest form of asset over there.
But you have to consider one critical point.
Text is foundation to everything online.
Getting started with assets
- Create an
assetsfolder in your “public” directory. - Drag images to the
public/assetsfolder and integrate them into your HTML files. - Preview the site by utilizing an HTTP server.
Learn more how from here.
- Enhance your development experience by adding the command to your
gitpod.ymlforbefore.npm install --global http-server - add the the
http-serverin the command.
Resolved Thought
While Terraform is primarily used for infrastructure provisioning, it can also be used for managing assets, offering opportunities to explore more functionality for beginners like You.
The question you may ask are;
- We added resources for specific single files like ‘index’ and ‘error’ pages.
- What if we want to add many files in a given directory e.g.
/assets?
The answer is, to handle multiple files, use a for_each loop in terraform.
Terrafoorm Console
- Learn about Terraform functions and complex types.
- Explore collection types in Terraform.
In the Terraform Console, obtain a list of all files in the public/assets directory.
- Run
terraform initfirst. - Run
terraform console. - Run the following to know where you stand exact;
path.rootA dot means you are in the root itself.
- Use the fileset function and explore more about it in the registry e.g. Lists all files
fileset("${path.root}/public/assets","*") - Filter in the console specific file types
fileset("${path.root}/public/assets","*.{jpg,png,gif}") - Filter in the console only jpg files.
fileset("${path.root}/public/assets","*.{jpg}") - Filter in the console only png files.
fileset("${path.root}/public/assets","*.{png}")
toset([
"elizabeth-7-deadly-sins.png",
])
- You can use Terraform’s output for further exploration in the Terraform Console.
In Terraform, you may find the need to cast things to other thing.
Calm, it’s a common Terraform development, you are not crazy.
Let’s get started with our for_each.
for each Configuration
- if we are using a list => will use a key
- if its more complex e.g map => we need key and value
The asset paths should not be hardcoded. Avoid it to perform a best practice.
- Navigate to
resource-storage.tfin your terrahouse module. - Define a resource for uploading assets.
resource "aws_s3_object" "upload_assets" {} - Add the
for_eachloop.for_each = fileset(<the-call>) - Consider making it more flexible by using TF variables.
var.assets_path,"*.{jpg,png,gif}"Grab the usual for the resource:
bucket,key,source,content type,etag. - assign the bucket the same way;
bucket = aws_s3_bucket.website_bucket.bucket - Change the
keyto go to the assets and do interpolation and each.key.key = "assets/${each.key}" - For
sourcepath root each dot key.source = "${var.assets_path}/${each.key}" etagis same assource.etag = filemd5("${var.assets_path}${each.key}")- Add the lifecycle as we previously did;
lifecycle { replace_triggered_by = [terraform_data.content_version.output] ignore_changes = [etag] } }
Also..exit out of console after done with the required configurations.
10. Testing and Verification
- Plan and verify the Terraform configuration.
- Ensure it properly handles assets. We can see it is doing the assets!
- Execute the apply to observe the asset management process.
Perfect! But.. read CamperBonus.
CamperBonus
We have to ensure that the asset paths are set as variables.
We may not want them to be hardcoded..
- Start by adding
vars.assets_pathin the asset configuration instead. - Define this variable in
module/variables.tf.variable "assets_path" { description = "Path to assets folder" type = string } - Add the variable to your module block in the root
main.tf.assets_path = var.assets_path # Add this line - Define it at the root level in
variables.tf.variable "assets_path" { description = "Path to assets folder" type = string } - Try terraform plan here;

- Add the actual variable to
terraform.tfvars.assets_path="/workspace/terraform-beginner-bootcamp-2023/public/assets" - Include it in
terraform.tfvars.samplefor use in your workspace.assets_path="/workspace/terraform-beginner-bootcamp-2023/public/assets" - Run tfp and observe the output.
- Check out your website with the assets;
My First TerraHome, Mixer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Great and cool!
Concluding;
Some assets from our great classmates;
{kind=link}
{kind=link}
TerraTown is the challenge for week 2, along with our custom provider!
But before we will have to present how you can work with git graphs.
See you soon!
Visuals with Git Graph
Terraformer! This is a great bonus for you to make sure you have git graph setup so you can observe everything you do with git, visualize history and address issues better.
NOTICE: This is primary deliverd as a two tags;
1.8.1: Installing and Adding git-log–graph Extension to Gitpod1.8.2: Installing and Adding mhutchie.git-graph Extension to Gitpod
I am merging that in 1.8.3.. |
|---|
| To maintain consistency in my project across tags, branches, and commits. |
Also. I will split the changes commits-based, specific to this branch, allowing your clear differentiation.
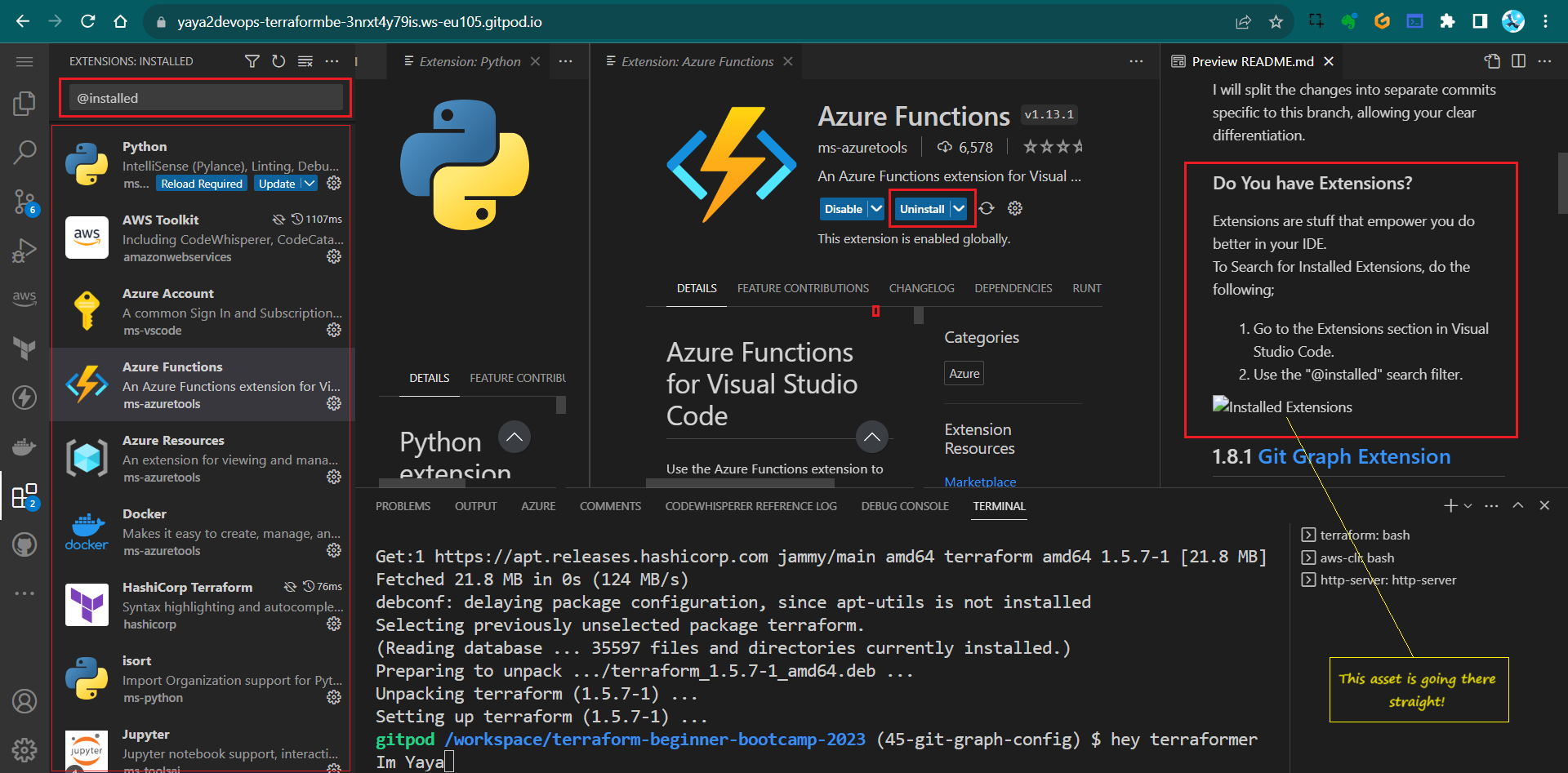
Do You have Extensions
Extensions are stuff that empower you do better in your IDE.
To Search for Installed Extensions, do the following;
- Go to the Extensions section in Visual Studio Code.
- Use the
@installedsearch filter.
1.8.1 Git Graph Extension¹
The objective is to address the Git graph issue by adding the Git Graph extension.
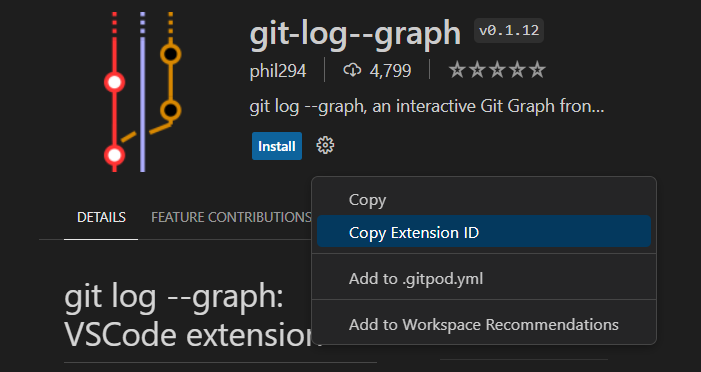
In this process, you have to search for and install Git-Log-Graph Extension:
- Search The required extension is “git-log–graph” in your IDE.
- Ensure that it’s installed.
- Abstract the extension ID from here.
- Add the copied line to your
gitpod.ymlconfiguration file.phil294.git-log--graph - Verify extension existence.
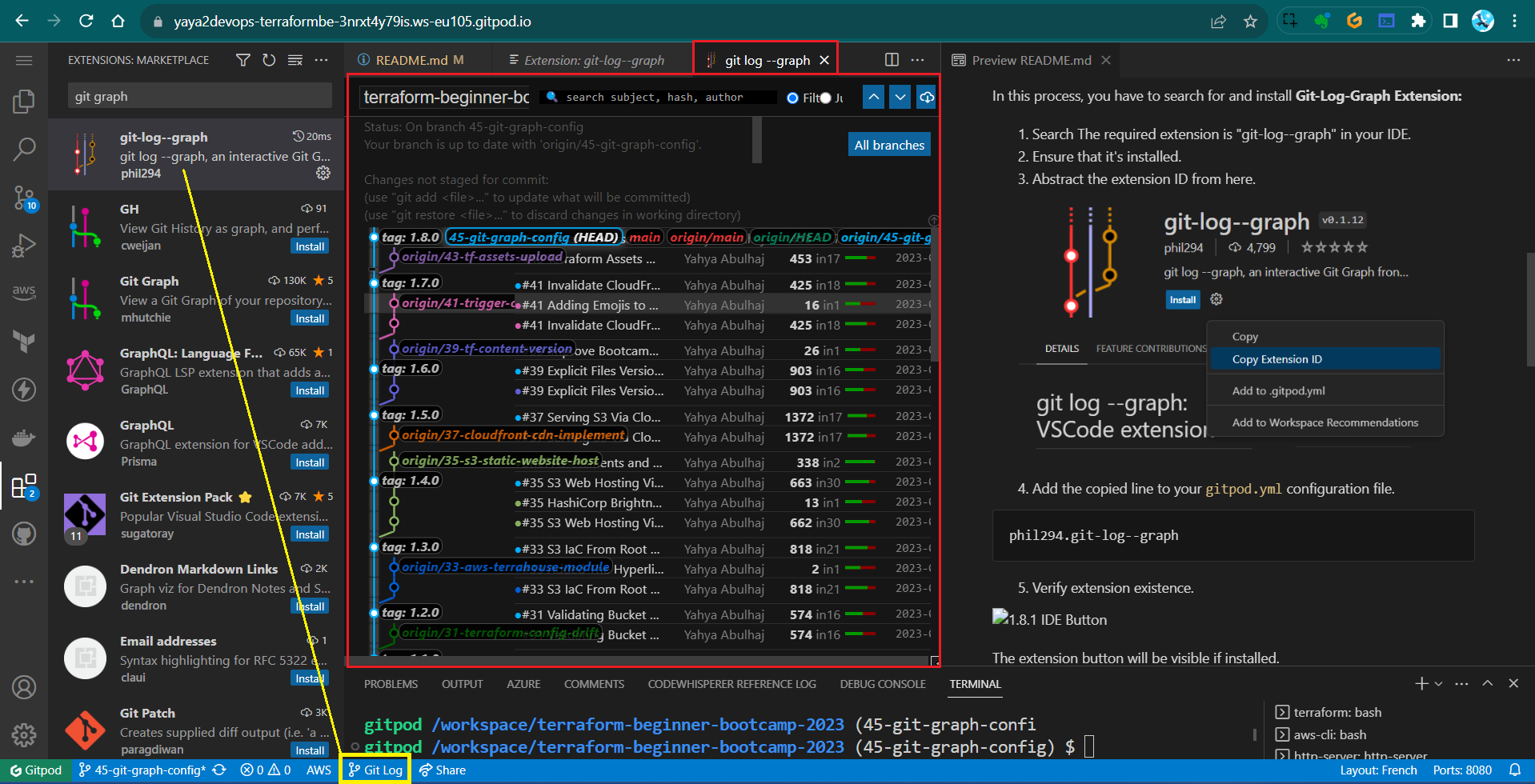
The extension button will be visible if installed.
1.8.1:
The tag is converted as a branch commit as explained above.
Related Commit: Install and Add git-log–graph to Gitpod task file.
1.8.2 Git Graph Extension²
We will Add the Git Graph (mhutchie.git-graph) extension to Gitpod to address the Git graph issue to enhance our experience.
The extension “mhutchie.git-graph” provides an alternative Git graph visualization.
Search for and install Git Graph Extension:
- To be specific, you can search “mhutchie.git-graph” in your IDE.
- Ensure that it’s installed.
- Abstract the extension ID from here.
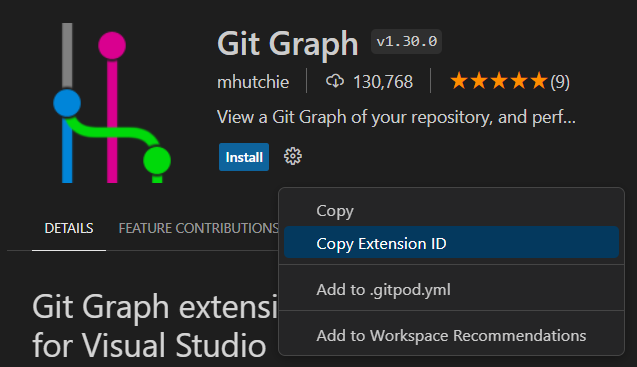
- Add the line copied to your
gitpod.ymlconfiguration file.mhutchie.git-graph - Verify extension existence.
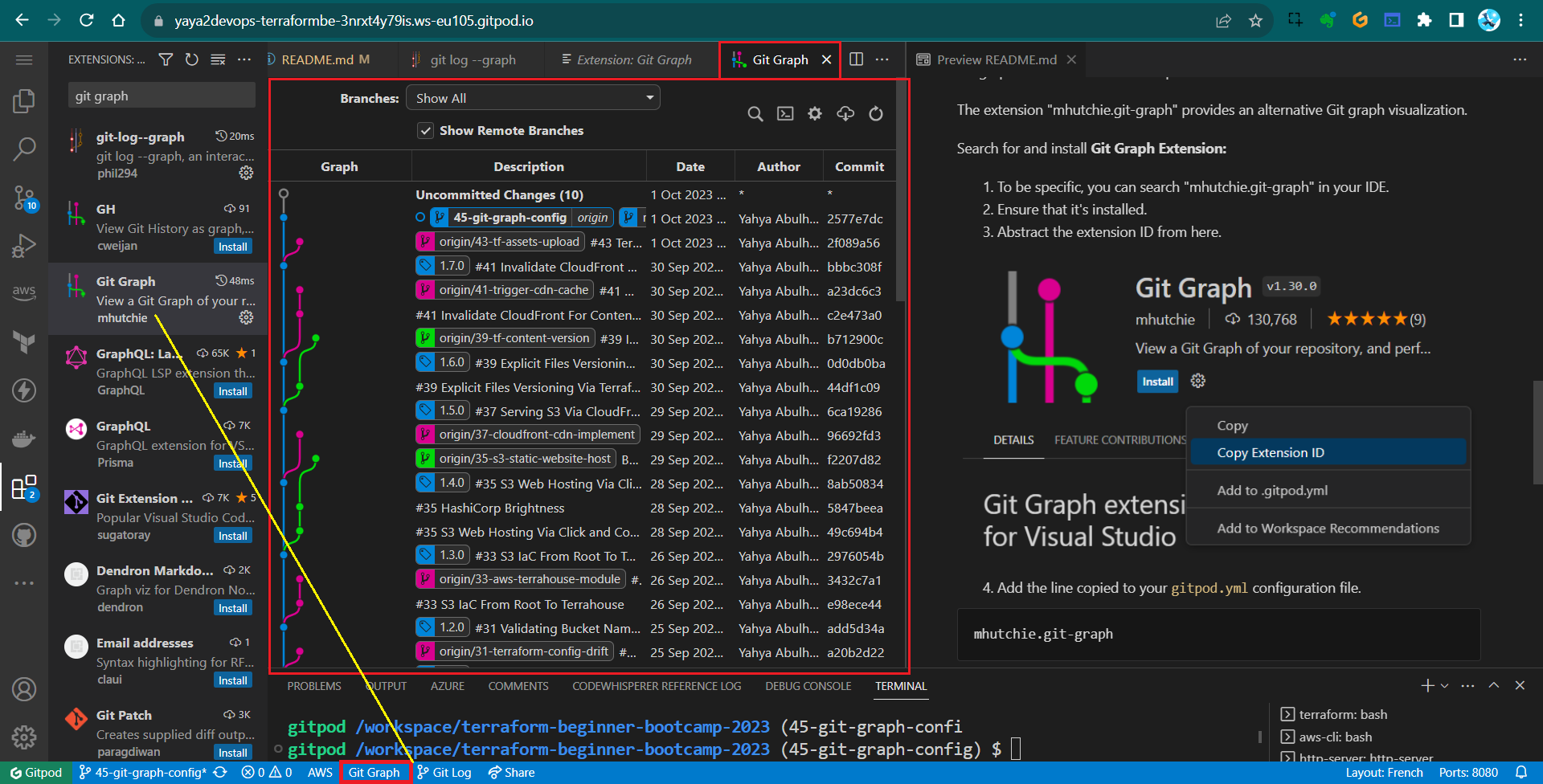
The extension button will be visible if installed.
This workflow differs from the usual stuff I do with Git X for local development, things change man.
1.8.2 Commit: Install and Add mhutchie.git-graph to Gitpod task file.
1.8.1 and 1.8.2 Relationship:
- Both are part of the same branch git-graph-config.
- Both are merged to single tag
1.8.3
I used small numbers..Also, I made this from notes using;
You can use my issue template for your own.
PS: GitLens is another good extension..
Well This Is Good
This week marks a significant phase in our journey.
I’ve chosen to call it a “transformation” for a very good reason.
During these past days, we’ve jumped deep into the heart of our project, immersing ourselves in the intricacies and complexities of our work. It’s been an opportunity to roll up our sleeves, dig into the nitty-gritty details, and truly understand the fundamental components.
As we move forward, you’ll find that your skills and understanding have expanded, enabling you to construct even more intricate terrahomes and undertake more ambitious projects.
Make sure to follow the last set, one last step, of instructions carefully.
Week 2 is pretty cool and crucial for mastering the intricacies of our craft
Go build the expertise needed to tackle challenges with confidence in your own universe.